Welcome to LightlyStudio!¶
LightlyStudio is an open-source tool designed to unify your data workflows from curation, annotation and management. Built with Rust for speed and efficiency, it lets you work seamlessly with datasets like COCO and ImageNet, even on a MacBook Pro with an M1 chip and 16 GB of memory.
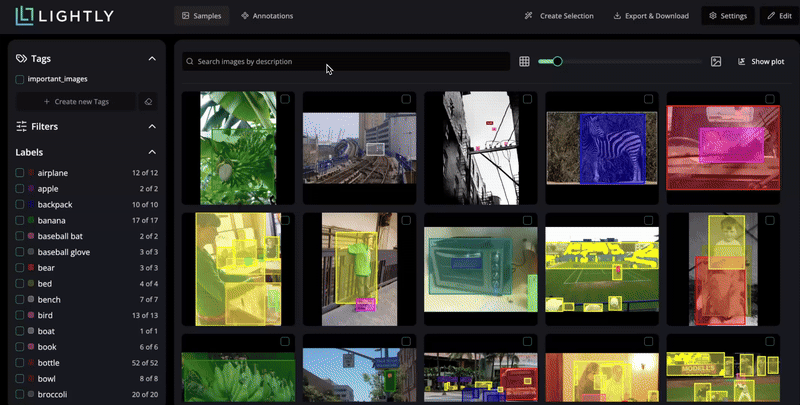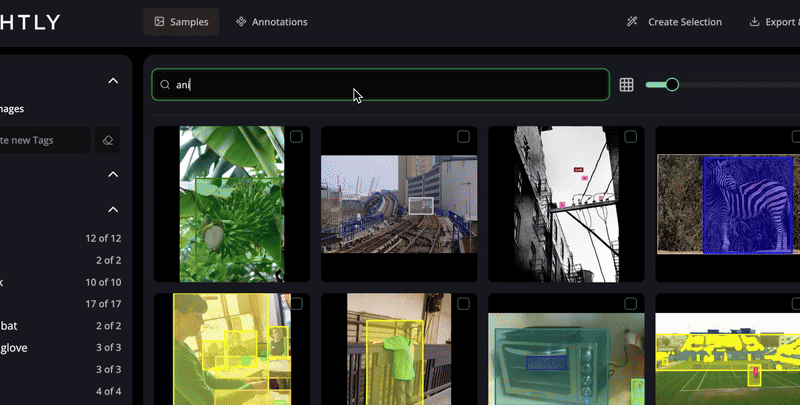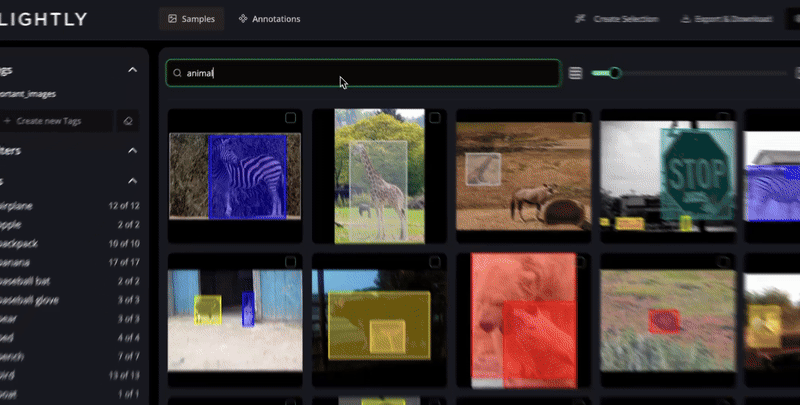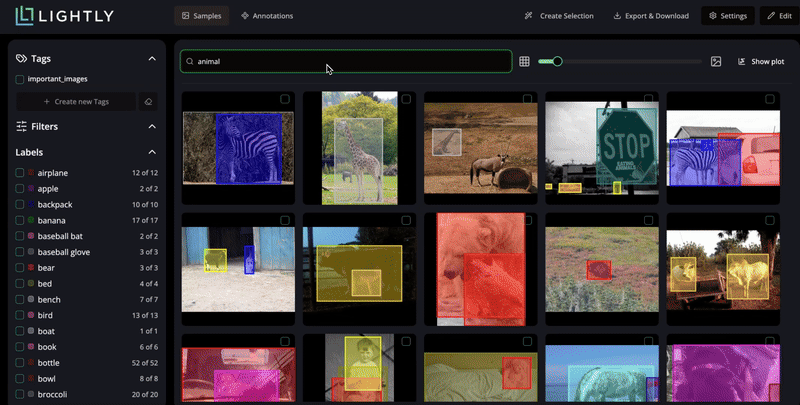 Discover insights instantly with AI-powered search and smart filters.
Learn more in Search and Filter.
Discover insights instantly with AI-powered search and smart filters.
Learn more in Search and Filter.
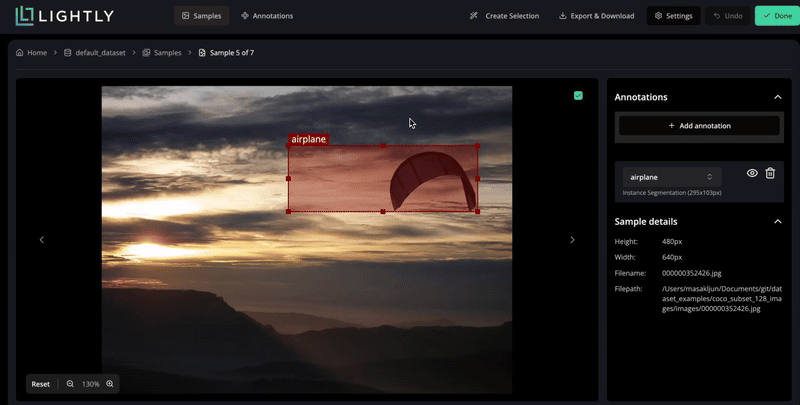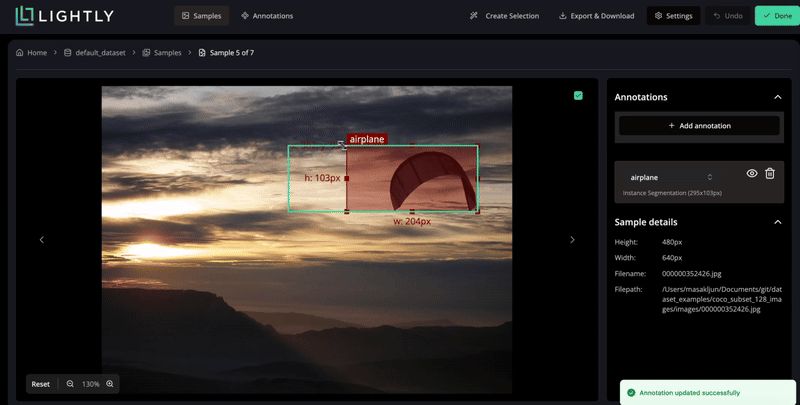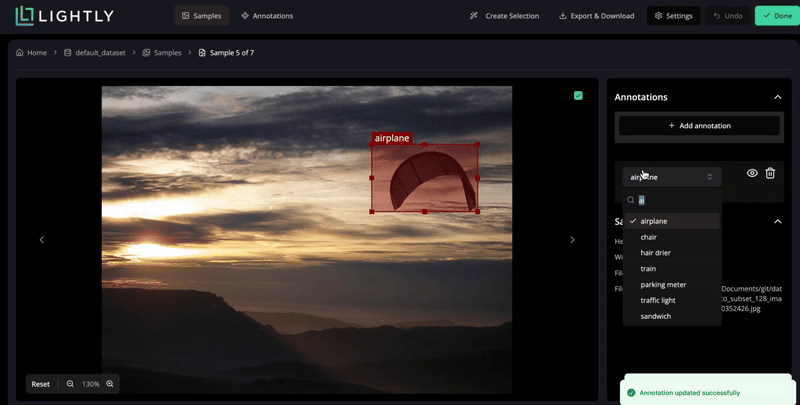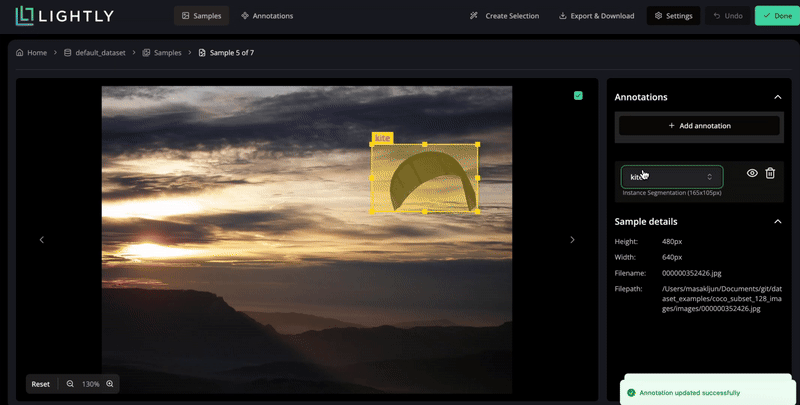 Create, edit, or remove annotations directly within your dataset.
Create, edit, or remove annotations directly within your dataset.
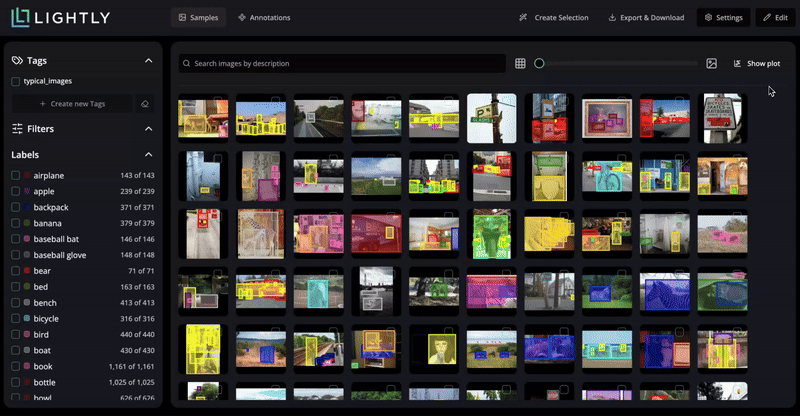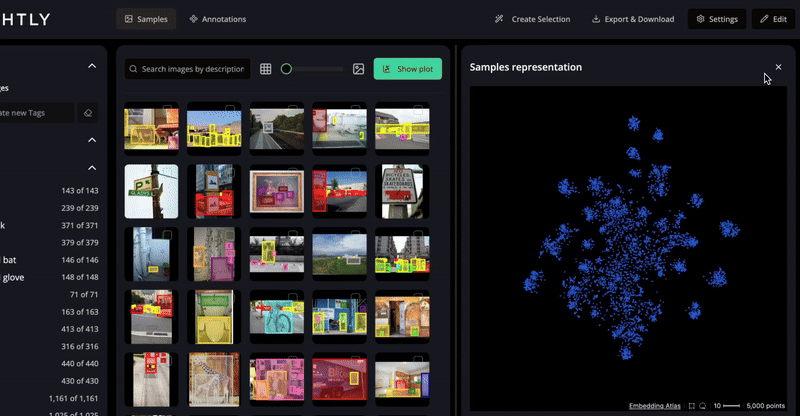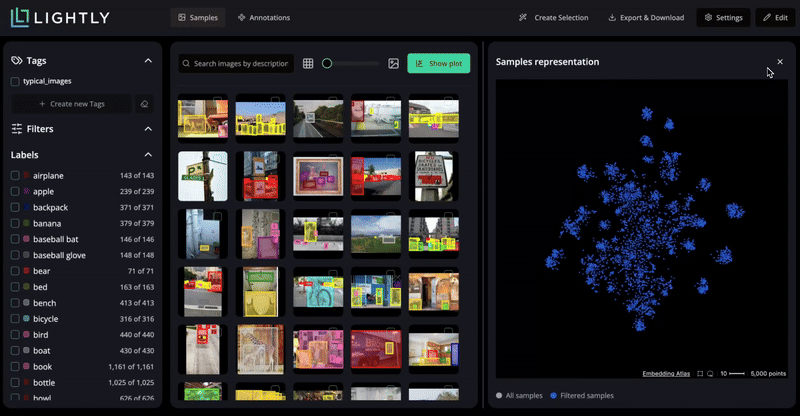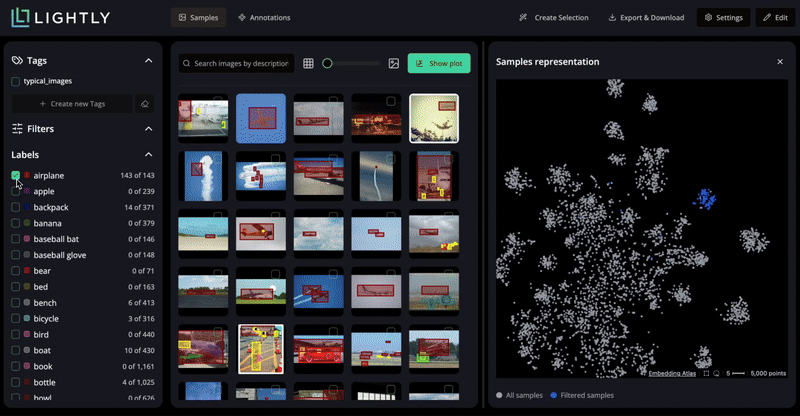 Visualize your dataset’s structure in the embedding space projected with PaCMAP.
Visualize your dataset’s structure in the embedding space projected with PaCMAP.
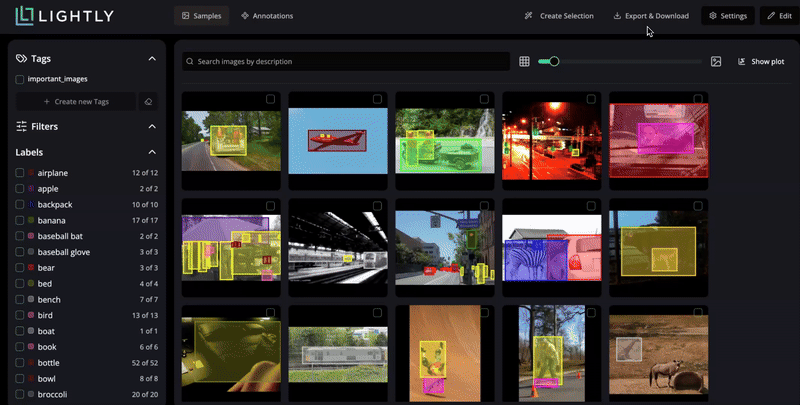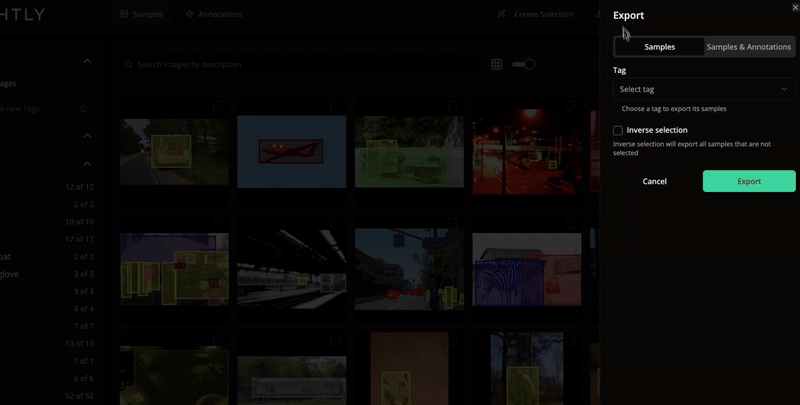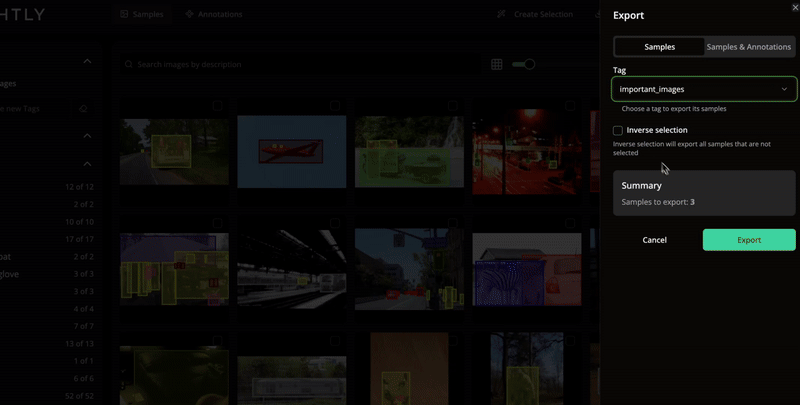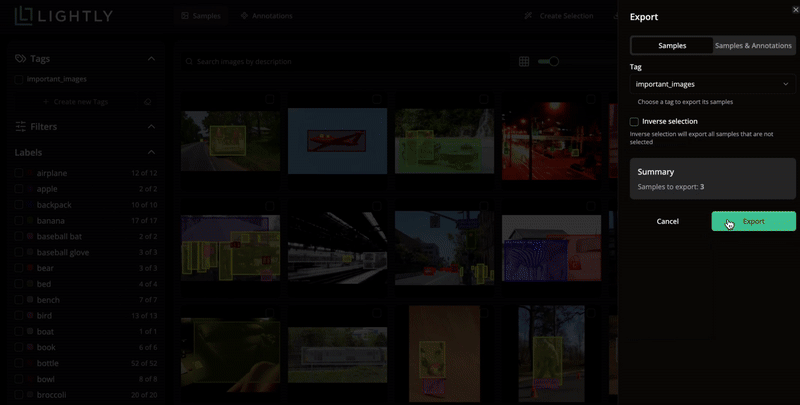 Export selected samples and annotations in your preferred format.
Export selected samples and annotations in your preferred format.
Installation¶
Ensure you have Python 3.9 to 3.14. We strongly recommend using a virtual environment.
The library is OS-independent and works on Windows, Linux, and macOS.
# 1. Create and activate a virtual environment (Recommended)
python3 -m venv venv
source venv/bin/activate
# 2. Install LightlyStudio
pip install lightly_studio
# 1. Create and activate a virtual environment (Recommended)
python -m venv venv
.\venv\Scripts\activate
# 2. Install LightlyStudio
pip install lightly_studio
Quickstart¶
The examples below download the required example data the first time you run them. You can also directly use your own image, video, or YOLO/COCO dataset.
-
Create a file named
example_image.pywith the following contents:example_image.pyimport lightly_studio as ls # Download the example dataset (will be skipped if it already exists) dataset_path = ls.utils.download_example_dataset(download_dir="dataset_examples") # Indexes the dataset, creates embeddings and stores everything in the database. dataset = ls.ImageDataset.create() dataset.add_images_from_path( path=f"{dataset_path}/coco_subset_128_images/images", ) # Start the UI server on localhost port 8001. # Pass `host` and `port` parameters to customize. ls.start_gui() -
Run
python example_image.pyin your terminal. - Click on the printed URL to open the app in your browser.
-
Create a file named
example_video.pywith the following contents:example_video.pyimport lightly_studio as ls # Download the example dataset (will be skipped if it already exists) dataset_path = ls.utils.download_example_dataset(download_dir="dataset_examples") # Create a dataset and populate it with videos. dataset = ls.VideoDataset.create() dataset.add_videos_from_path(path=f"{dataset_path}/youtube_vis_50_videos/train/videos") # Start the UI server. ls.start_gui() -
Run
python example_video.pyin your terminal. - Click on the printed URL to open the app in your browser.
-
Create a file named
example_yolo.pywith the following contents:example_yolo.pyimport lightly_studio as ls # Download the example dataset (will be skipped if it already exists) dataset_path = ls.utils.download_example_dataset(download_dir="dataset_examples") dataset = ls.ImageDataset.create() dataset.add_samples_from_yolo( data_yaml=f"{dataset_path}/road_signs_yolo/data.yaml", ) ls.start_gui() -
Run
python example_yolo.pyin your terminal. - Click on the printed URL to open the app in your browser.
-
Create a file named
example_coco.pywith the following contents:example_coco.pyimport lightly_studio as ls # Download the example dataset (will be skipped if it already exists) dataset_path = ls.utils.download_example_dataset(download_dir="dataset_examples") dataset = ls.ImageDataset.create() dataset.add_samples_from_coco( annotations_json=f"{dataset_path}/coco_subset_128_images/instances_train2017.json", images_path=f"{dataset_path}/coco_subset_128_images/images", annotation_type=ls.AnnotationType.INSTANCE_SEGMENTATION, ) ls.start_gui() -
Run
python example_coco.pyin your terminal. - Click on the printed URL to open the app in your browser.
How It Works
- Your Python script creates a LightlyStudio dataset.
- The
dataset.add_<samples>_from_<source>functions read your samples and annotations, calculate embeddings, and save metadata to a locallightly_studio.dbfile (using DuckDB). ls.start_gui()starts a local backend API server.- This server reads from
lightly_studio.dband serves data to the UI Application running in your browser (by defaulthttp://localhost:8001). - Images and videos are streamed from their original local folder or remote storage for display in the UI.
For Linux Users
We recommend using Firefox for the best experience with embedding plots, as other browsers might not render them correctly.
Feature Overview¶
Datasets¶


Concepts¶


Tools¶




Python API¶
LightlyStudio has a powerful Python interface. You can not only index datasets but also query and manipulate them using code. It supports local and cloud-hosted image and video folders; see Using Cloud Storage for setup and limitations.