Object Detection with Ultralytics’ YOLO¶
This tutorial demonstrates how to pretrain a YOLO model using LightlyTrain and then fine-tune it for object detection using the ultralytics framework. To this end, we will first pretrain on a 25k image subset of the COCO dataset (only the images, no labels!), and subsequently finetune on the labeled PASCAL VOC dataset.
Warning
Using Ultralytics models might require a commercial Ultralytics license. See the Ultralytics website for more information.
Install Dependencies¶
Install the required packages:
lightly-trainfor pretraining, with support forultralytics’ YOLO modelssupervisionto visualize some of the annotated pictures
pip install "lightly-train[ultralytics]" "supervision==0.25.1"
Pretraining on COCO-minitrain¶
Time for some magic! We’ll first grab the COCO-minitrain dataset (25k images) directly from HuggingFace…
wget https://huggingface.co/datasets/bryanbocao/coco_minitrain/resolve/main/coco_minitrain_25k.zip
… unzip it…
unzip coco_minitrain_25k.zip
… and since LightlyTrain does not require any labels, we can can confidently delete all the labels:
rm -rf coco_minitrain_25k/labels
With the dataset ready, we can now start the pretraining. Pretraining with LightlyTrain could not be easier, you just pass the following parameters:
out: you simply state where you want your logs and exported model to go tomodel: the model that you want to train, e.g.yolo11sfrom Ultralyticsdata: the path to a folder with images
Your data is simply assumed to be an arbitrarily nested folder; LightlyTrain with find all images on its own and since there are no labels required there is no danger of ever using false labels! 🕵️♂️
# pretrain_yolo.py
import lightly_train
if __name__ == "__main__":
# Pretrain with LightlyTrain.
lightly_train.train(
out="out/coco_minitrain_pretrain", # Output directory.
model="ultralytics/yolo11s.yaml", # Pass the YOLO model (use .yaml ending to start with random weights).
data="coco_minitrain_25k/images", # Path to a directory with training images.
epochs=100, # Adjust epochs for shorter training.
batch_size=128, # Adjust batch size based on hardware.
)
lightly-train --out=out/coco_minitrain_pretrain --model=ultralytics/yolo11s.yaml --data=coco_minitrain_25k/images --epochs=100 --batch-size=128
And just like that you pretrained a YOLO11s backbone! 🥳 This backbone can’t solve any task yet, so in the next step we will finetune it on the PASCAL VOC dataset.
Finetuning on PASCAL VOC¶
Now that the pretrained model has been exported, we will further fine-tune the model on the task of object detection. The exported model already has exactly the format that Ultralytics’ YOLO expects, so after getting the dataset ready, we can get started with only a few lines! ⚡️
In addition to fine-tuning the pretrained model we will also train a model that we initialize with random weights. This will let us compare the performance between the two, and show the great benefits of pretraining.
Download the PASCAL VOC Dataset¶
We can download the dataset directly using Ultralytics’ API with the check_det_dataset function:
from ultralytics.data.utils import check_det_dataset
dataset = check_det_dataset("VOC.yaml")
Ultralytics always downloads your datasets to a fixed location, which you can fetch via their settings module:
from ultralytics import settings
print(settings["datasets_dir"])
Inside that directory (
tree -d <DATASET-DIR>/VOC -I VOCdevkit
> datasets/VOC
> ├── images
> │ ├── test2007
> │ ├── train2007
> │ ├── train2012
> │ ├── val2007
> │ └── val2012
> └── labels
> ├── test2007
> ├── train2007
> ├── train2012
> ├── val2007
> └── val2012
Inspect a few Images¶
Let’s use supervision and look at a few of the annotated samples to get a feeling of what the data looks like:
import random
import matplotlib.pyplot as plt
import supervision as sv
import yaml
from ultralytics import settings
from ultralytics.data.utils import check_det_dataset
dataset = check_det_dataset("VOC.yaml")
detections = sv.DetectionDataset.from_yolo(
data_yaml_path=dataset["yaml_file"],
images_directory_path=f"{settings['datasets_dir']}/VOC/images/train2012",
annotations_directory_path=f"{settings['datasets_dir']}/VOC/labels/train2012",
)
with open(dataset["yaml_file"], "r") as f:
data = yaml.safe_load(f)
names = data["names"]
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
fig, ax = plt.subplots(2, 2, figsize=(10, 10))
ax = ax.flatten()
detections = [detections[random.randint(0, len(detections))] for _ in range(4)]
for i, (path, image, annotation) in enumerate(detections):
annotated_image = box_annotator.annotate(scene=image, detections=annotation)
annotated_image = label_annotator.annotate(
scene=annotated_image,
detections=annotation,
labels=[names[elem] for elem in annotation.class_id],
)
ax[i].imshow(annotated_image[..., ::-1])
ax[i].axis("off")
fig.tight_layout()
fig.show()

Finetuning the Pretrained Model¶
All we have to do is to pass the path to the pretrained model to the YOLO class and the rest is the same as always with Ultralytics.
# finetune_yolo.py
from ultralytics import YOLO
if __name__ == "__main__":
# Load the exported model.
model = YOLO("out/coco_minitrain_pretrain/exported_models/exported_last.pt")
# Fine-tune with ultralytics.
model.train(data="VOC.yaml", epochs=30, project="logs/voc_yolo11s", name="from_pretrained")
yolo detect train model="out/my_experiment/exported_models/exported_last.pt" data="VOC.yaml" epochs=30 project="logs/voc_yolo11s" name="from_pretrained"
Finetuning the Randomly Initialized Model¶
In order to quantify the influence of our pretraining, we also train a model from random weights, in Ultralytics this follows the .yaml name convention.
# finetune_scratch_yolo.py
from ultralytics import YOLO
if __name__ == "__main__":
# Load the exported model.
model = YOLO("yolo11s.yaml") # randomly initialized model
# Fine-tune with ultralytics.
model.train(data="VOC.yaml", epochs=30, project="logs/voc_yolo11s", name="from_scratch")
yolo detect train model="yolo11s.yaml" data="VOC.yaml" epochs=30 project="logs/voc_yolo11s" name="from_scratch"
Evaluating the Model Performance¶
Congratulations, you made it almost to the end! 🎉 The last thing we’ll do is to analyze the performance between the two. A very common metric to measure the performance of object detectors is the mAP50-95 which we plot in the next cell, for both the pretrained model and the model that we trained from scratch.
import matplotlib.pyplot as plt
import pandas as pd
res_scratch = pd.read_csv("logs/voc_yolo11s/from_scratch/results.csv")
res_finetune = pd.read_csv("logs/voc_yolo11s/from_pretrained/results.csv")
fig, ax = plt.subplots()
ax.plot(res_scratch["epoch"], res_scratch["metrics/mAP50-95(B)"], label="scratch")
ax.plot(res_finetune["epoch"], res_finetune["metrics/mAP50-95(B)"], label="finetune")
ax.set_xlabel("Epoch")
ax.set_ylabel("mAP50-95")
max_pretrained = res_finetune["metrics/mAP50-95(B)"].max()
max_scratch = res_scratch["metrics/mAP50-95(B)"].max()
ax.set_title(
f"Pretraining is {(max_pretrained - max_scratch) / max_scratch * 100:.2f}% better than scratch"
)
ax.legend()
plt.show()
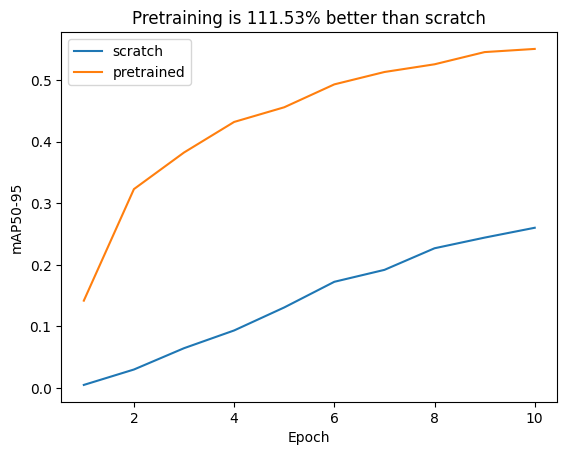
As clearly visible in the plot, the pretrained models converges much faster and achieves a significantly higher mAP50-95 than the model trained from scratch!
Next Steps¶
Congratulations, you’ve mastered the basics! 🎉 Ready to take it further? Here are some exciting next steps:
Go beyond distillation and explore other pretraining methods in LightlyTrain. Check Methods for more exciting possibilities!
Try your hand at different YOLO flavors (
YOLOv5,YOLOv6,YOLOv8).Take your pretrained model for a spin with image embeddings and similarity search.
Happy experimenting! 🚀