Semantic Segmentation¶
![]()
Note
LightlyTrain now supports training DINOv3 and DINOv2 models for semantic segmentation with the train_semantic_segmentation function! The method is based on the
state-of-the-art segmentation model EoMT by
Kerssies et al. and reaches 59.1% mIoU with DINOv3 weights and 58.4% mIoU with DINOv2 weights on the ADE20k dataset.
Benchmark Results¶
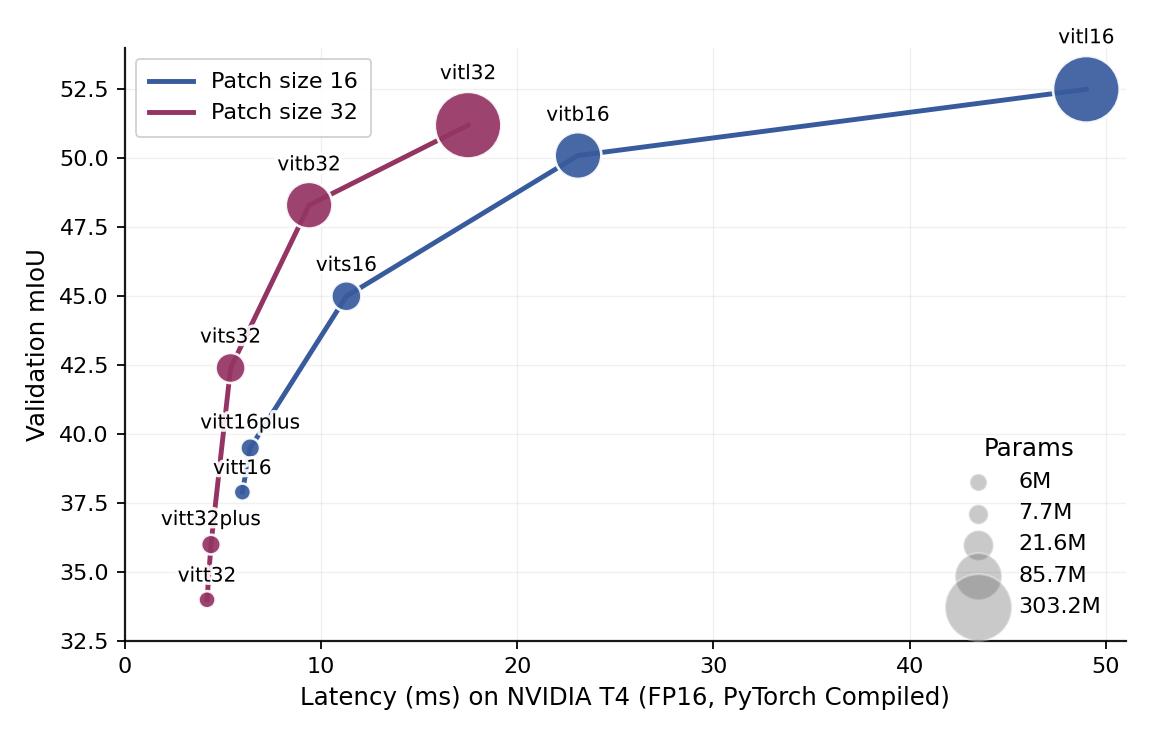
Below we provide the model checkpoints and report the validation mIoUs and inference latency of three different DINOv3 models fine-tuned on various datasets with LightlyTrain. We also made the comparison to the results obtained in the original EoMT paper, if available. You can check here for how to use these model checkpoints for further fine-tuning.
The experiments, unless stated otherwise, generally follow the protocol in the original
EoMT paper, using a batch size of 16 and a learning rate of 1e-4. The average
latency values were measured with model compilation using torch.compile on a single
NVIDIA T4 GPU with FP16 precision.
You can also explore inferencing with these model weights using our Colab notebook:
![]()
COCO-Stuff¶
Patch size 16 models are more accurate but slower; patch size 32 models are faster
but slightly less accurate. Pick the variant that fits your speed/accuracy trade-off.
Patch size 16 (higher accuracy, slower):
Implementation |
Model |
Val mIoU |
Avg. Latency (ms) |
Params (M) |
Input Size |
|---|---|---|---|---|---|
LightlyTrain |
dinov3/vitt16-eomt-coco |
37.9 |
6.0 |
6.0 |
512×512 |
LightlyTrain |
dinov3/vitt16plus-eomt-coco |
39.5 |
6.4 |
7.7 |
512×512 |
LightlyTrain |
dinov3/vits16-eomt-coco |
45.0 |
11.3 |
21.6 |
512×512 |
LightlyTrain |
dinov3/vitb16-eomt-coco |
50.1 |
23.1 |
85.7 |
512×512 |
LightlyTrain |
dinov3/vitl16-eomt-coco |
52.5 |
49.0 |
303.2 |
512×512 |
Patch size 32 (faster, lower accuracy):
Implementation |
Model |
Val mIoU |
Avg. Latency (ms) |
Params (M) |
Input Size |
|---|---|---|---|---|---|
LightlyTrain |
dinov3/vitt32-eomt-coco |
34.0 |
4.2 |
6.0 |
512×512 |
LightlyTrain |
dinov3/vitt32plus-eomt-coco |
36.0 |
4.4 |
7.7 |
512×512 |
LightlyTrain |
dinov3/vits32-eomt-coco |
42.4 |
5.4 |
21.6 |
512×512 |
LightlyTrain |
dinov3/vitb32-eomt-coco |
48.3 |
9.4 |
85.7 |
512×512 |
LightlyTrain |
dinov3/vitl32-eomt-coco |
51.2 |
17.5 |
303.2 |
512×512 |
We trained with 12 epochs (~88k steps) on the COCO-Stuff dataset with num_queries=200
for EoMT.
Cityscapes¶
Implementation |
Model |
Val mIoU |
Avg. Latency (ms) |
Params (M) |
Input Size |
|---|---|---|---|---|---|
LightlyTrain |
dinov3/vits16-eomt-cityscapes |
78.6 |
53.8 |
21.6 |
1024×1024 |
LightlyTrain |
dinov3/vitb16-eomt-cityscapes |
81.0 |
114.9 |
85.7 |
1024×1024 |
LightlyTrain |
dinov3/vitl16-eomt-cityscapes |
84.4 |
256.4 |
303.2 |
1024×1024 |
Original EoMT |
dinov2/vitl16-eomt |
84.2 |
- |
319 |
1024×1024 |
We trained with 107 epochs (~20k steps) on the Cityscapes dataset with num_queries=200
for EoMT.
Semantic Segmentation with EoMT¶
![]()
Training a semantic segmentation model with LightlyTrain is straightforward and only requires a few lines of code. See data for more details on how to prepare your dataset.
Train a Semantic Segmentation Model¶
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov2/vitl14-eomt",
data={
"train": {
"images": "my_data_dir/train/images", # Path to training images
"masks": "my_data_dir/train/masks", # Path to training masks
},
"val": {
"images": "my_data_dir/val/images", # Path to validation images
"masks": "my_data_dir/val/masks", # Path to validation masks
},
"classes": { # Classes in the dataset
0: "background",
1: "car",
2: "bicycle",
# ...
},
# Optional, classes that are in the dataset but should be ignored during
# training.
"ignore_classes": [0],
},
)
During training, both the
best (with highest validation mIoU) and
last (last validation round as determined by
save_checkpoint_args.save_every_num_steps)
model weights are exported to out/my_experiment/exported_models/, unless disabled in
save_checkpoint_args. You can use
these weights to continue fine-tuning on another task by loading the weights via the
model argument:
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="out/my_experiment/exported_models/exported_best.pt", # Continue training from the best model
data={...},
)
Note
Check here for how to use the LightlyTrain model checkpoints for further fine-tuning.
Load the Trained Model from Checkpoint and Predict¶
After the training completes, you can load the best model checkpoints for inference like this:
import lightly_train
model = lightly_train.load_model("out/my_experiment/exported_models/exported_best.pt")
masks = model.predict("path/to/image.jpg")
# Masks is a tensor of shape (height, width) with class labels as values.
# It has the same height and width as the input image.
Visualize the Result¶
After making the predictions with the model weights, you can visualize the predicted masks like this:
import matplotlib.pyplot as plt
import torch
from torchvision.io import read_image
from torchvision.utils import draw_segmentation_masks
image = read_image("path/to/image.jpg")
masks = torch.stack([masks == class_id for class_id in masks.unique()])
image_with_masks = draw_segmentation_masks(image, masks, alpha=0.6)
plt.imshow(image_with_masks.permute(1, 2, 0))
The predicted masks have shape (height, width) and each value corresponds to a class
ID as defined in the classes dictionary in the dataset.
Use EoMT with DINOv3¶
To fine-tune EoMT from DINOv3, you have to set model to one of the
DINOv3 models.
Note
DINOv3 models are released under the DINOv3 license.
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov3/vits16-eomt",
data={
"train": {
"images": "my_data_dir/train/images", # Path to training images
"masks": "my_data_dir/train/masks", # Path to training masks
},
"val": {
"images": "my_data_dir/val/images", # Path to validation images
"masks": "my_data_dir/val/masks", # Path to validation masks
},
"classes": { # Classes in the dataset
0: "background",
1: "car",
2: "bicycle",
# ...
},
# Optional, classes that are in the dataset but should be ignored during
# training.
"ignore_classes": [0],
},
)
Changing the Patch Size¶
Increasing the patch size is an effective way to speed up inference and training. The
patch size is encoded in the model name: for DINOv3 ViT models, dinov3/vits16-eomt
uses a patch size of 16, while dinov3/vits32-eomt uses a patch size of 32. To train at
a larger patch size, simply select a vit*32 model:
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov3/vits32-eomt-coco",
# ...,
)
The patch-32 checkpoints are derived from the corresponding patch-16 pretrained weights by resizing the patch embedding using the method introduced in FlexiViT, so the pretrained weights remain compatible. The available models are listed here in the “Model” column of the tables.
As illustrated in this figure, increasing the patch size leads to a significant speed-up with only a moderate impact on performance.
Use the LightlyTrain Model Checkpoints¶
Now you can also start with the DINOv3 model checkpoints that LightlyTrain provides. The models are listed here in the “Model” column of the tables.
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov3/vits16-eomt-coco", # Use the COCO-Stuff model checkpoint for further fine-tuning
data={...},
)
Out¶
The out argument specifies the output directory
where all training logs, model exports, and checkpoints are saved. It looks like this
after training:
out/my_experiment
├── checkpoints
│ └── last.ckpt # Last checkpoint
├── exported_models
| └── exported_last.pt # Last model exported (unless disabled)
| └── exported_best.pt # Best model exported (unless disabled)
├── events.out.tfevents.1721899772.host.1839736.0 # TensorBoard logs
└── train.log # Training logs
The final model checkpoint is saved to out/my_experiment/checkpoints/last.ckpt. The
last and best model weights are exported to out/my_experiment/exported_models/ unless
disabled in save_checkpoint_args.
Tip
Create a new output directory for each experiment to keep training logs, model exports, and checkpoints organized.
Data¶
LightlyTrain supports training semantic segmentation models with images and masks. Every image must have a corresponding mask whose filename either matches that of the image (under a different directory) or follows a specific template pattern. The masks must be PNG images in either grayscale integer format, where each pixel value corresponds to a class ID, or multi-channel (e.g., RGB) format.
The data argument accepts either a dictionary or a path to a YAML file containing the
same configuration. When loading from YAML, relative paths are resolved relative to the
YAML file. Unknown top-level YAML keys are ignored, but unknown nested keys still raise
a validation error. Training uses the train and val splits.
The following image formats are supported:
jpg
jpeg
png
ppm
bmp
pgm
tif
tiff
webp
dcm (DICOM)
For more details on LightlyTrain’s support for data input, please check the Data Input page.
The following mask formats are supported:
png
Specify Mask Filepaths¶
We support two ways of specifying the mask filepaths in relation to the image filepaths:
Using the same filename as the image but under a different directory.
Using a template against the image filepath.
Using the Same Filename as the Image¶
We support loading masks that share the same filenames as their corresponding images under different directories. Here is an example of such a directory structure with training and validation images and masks:
my_data_dir
├── train
│ ├── images
│ │ ├── image0.jpg
│ │ └── image1.jpg
│ └── masks
│ ├── image0.png
│ └── image1.png
└── val
├── images
| ├── image2.jpg
| └── image3.jpg
└── masks
├── image2.png
└── image3.png
To train with this directory structure, set the data argument like this:
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov2/vitl14-eomt",
data={
"train": {
"images": "my_data_dir/train/images", # Path to training images
"masks": "my_data_dir/train/masks", # Path to training masks
},
"val": {
"images": "my_data_dir/val/images", # Path to validation images
"masks": "my_data_dir/val/masks", # Path to validation masks
},
"classes": { # Classes in the dataset
0: "background",
1: "car",
2: "bicycle",
# ...
},
# Optional, classes that are in the dataset but should be ignored during
# training.
"ignore_classes": [0],
},
)
The classes in the dataset must be specified in the classes dictionary. The keys are
the class IDs and the values are the class names. The class IDs must be identical to the
values in the mask images. All possible class IDs must be specified, otherwise
LightlyTrain will raise an error if an unknown class ID is encountered. If you would
like to ignore some classes during training, you specify their class IDs in the
ignore_classes argument. The trained model will then not predict these classes.
Using a Template against the Image Filepath¶
We also support loading masks that follow a certain template against the corresponding image filepath. For example, if you have the following directory structure:
my_data_dir
├── train
│ ├── images
│ │ ├── image0.jpg
│ │ └── image1.jpg
│ └── masks
│ ├── image0_mask.png
│ └── image1_mask.png
└── val
├── images
| ├── image2.jpg
| └── image3.jpg
└── masks
├── image2_mask.png
└── image3_mask.png
you could set the data argument like this:
import lightly_train
if __name__ == "__main__":
mask_file = "{image_path.parent.parent}/masks/{image_path.stem}_mask.png"
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov2/vitl14-eomt",
data={
"train": {
"images": "my_data_dir/train/images",
"masks": mask_file, # This will match masks with the same filename stem as the training image but with a `_mask` suffix in "my_data_dir/train/masks" in PNG format
},
"val": {
"images": "my_data_dir/val/images",
"masks": mask_file, # This will match masks with the same filename stem as the training image but with a `_mask` suffix in "my_data_dir/val/masks" in PNG format
},
"classes": { # Classes in the dataset
0: "background",
1: "car",
2: "bicycle",
# ...
},
# Optional, classes that are in the dataset but should be ignored during
# training.
"ignore_classes": [0],
},
)
The template string always uses image_path (of type pathlib.Path) to refer to the
filepath of the corresponding image. Only this parameter is allowed in the template
string, which is used to calculate the mask filepath.
Specify Training Classes¶
We support two mask formats:
Single-channel integer masks, where each integer value determines a label
Multi-channel masks (e.g., RGB masks), where each pixel value determines a label
Use classes in the data dict to map class IDs to labels. In this document, a class
ID is a key in the classes dictionary and a label is its value.
Using Integer Masks¶
For single-channel integer masks (each pixel value is a label), the default is a direct mapping from class IDs to label names:
"classes": {
0: "background",
1: "car",
2: "bicycle",
# ...
},
Alternatively, to merge multiple labels into one class during training, use a dictionary like the following:
"classes": {
0: "background",
1: {"name": "vehicle", "labels": [1, 2]}, # Merge label 1 and 2 into "vehicle" with class ID 1
# ...
},
Or:
"classes": {
0: {"name": "background", "labels": [0]},
1: {"name": "vehicle", "labels": [1, 2]},
# ...
},
It is fine if original labels coincide with class IDs, as in the example. Only the class IDs are used for the internal classes for training and prediction masks. Note that each label can map to only one class ID.
Using Multi-channel Masks¶
For multi-channel masks, specify pixel values as lists of integer tuples (type
list[tuple[int, ...]]) in the "labels" field:
"classes": {
0: {"name": "unlabeled", "labels": [(0, 0, 0), (255, 255, 255)]}, # (0,0,0) and (255,255,255) will be mapped to class "unlabeled" with class ID 0
1: {"name": "road", "labels": [(128, 128, 128)]},
},
These pixel values are converted to class IDs internally during training. Predictions
are single-channel masks with those class IDs. Again, each label can map to only one
class ID, and you cannot mix integer and tuple-valued labels in a single classes
dictionary.
Loading Classes from a JSON File¶
Instead of specifying classes inline, you can pass a path to a .json file directly
as the classes value. The JSON file supports the same formats as the inline classes
dict.
Simple format — maps each class ID to a name (label defaults to the class ID):
{
"0": "background",
"1": "airplane",
"2": "car",
"3": "bicycle"
}
Single-channel with explicit labels — merges multiple mask labels into one class:
{
"0": {"name": "background", "labels": [0, 1]},
"1": {"name": "vehicle", "labels": [2, 3]}
}
Multi-channel — maps RGB (or other multi-channel) pixel tuples to class IDs:
{
"0": {"name": "background", "labels": [[0, 0, 0], [255, 255, 255]]},
"1": {"name": "road", "labels": [[128, 128, 128]]}
}
Pass the path to this file as classes:
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov2/vitl14-eomt",
data={
"train": {
"images": "my_data_dir/train/images",
"masks": "my_data_dir/train/masks",
},
"val": {
"images": "my_data_dir/val/images",
"masks": "my_data_dir/val/masks",
},
"classes": "my_data_dir/classes.json", # Path to the JSON class mapping file
"ignore_classes": [0],
},
)
Model¶
The model argument defines the model used for
semantic segmentation training. The following models are available:
DINOv3 Models¶
dinov3/vitt32-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vitt32plus-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vits32-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vitb32-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vitl32-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vitt16-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vitt16plus-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vits16-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vitb16-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vitl16-eomt-coco(fine-tuned on COCO-Stuff)dinov3/vits16-eomt-cityscapes(fine-tuned on Cityscapes)dinov3/vitb16-eomt-cityscapes(fine-tuned on Cityscapes)dinov3/vitl16-eomt-cityscapes(fine-tuned on Cityscapes)dinov3/vitt16-eomtdinov3/vitt16-eupe-eomt- EUPE weightsdinov3/vitt16plus-eomtdinov3/vits16-eomtdinov3/vits16-eupe-eomt- EUPE weightsdinov3/vits16-lingbot-eomt- LingBot Vision weightsdinov3/vits16plus-eomtdinov3/vitb16-eomtdinov3/vitb16-eupe-eomt- EUPE weightsdinov3/vitb16-lingbot-eomt- LingBot Vision weightsdinov3/vitl16-eomtdinov3/vitl16-lingbot-eomt- LingBot Vision weightsdinov3/vitl16plus-eomtdinov3/vith16plus-eomtdinov3/vit7b16-eomt
Unless noted otherwise, all DINOv3 backbones are initialized from weights
pretrained by Meta.
The non-EUPE models with vitt16 and vitt16plus backbones use Lightly-pretrained
DINOv3 backbone weights instead. Models marked as EUPE use
EUPE weights. DINOv3 models are under the
DINOv3 license. EUPE
models are under the
FAIR Noncommercial Research License.
Models marked as LingBot use
LingBot Vision weights, which are released
under the
Apache 2.0 license.
As they are built on DINOv3, the terms of the
DINOv3 license also
apply to these models.
DINOv2 Models¶
dinov2/vits14-eomtdinov2/vitb14-eomtdinov2/vitl14-eomtdinov2/vitg14-eomt
All DINOv2 models are pretrained by Meta.
Training Settings¶
See Train Settings on how to configure training settings.
Logging¶
See Logging on how to configure logging.
Resume Training¶
See Resume Training on how to resume training.
Pretrain and Fine-tune a Semantic Segmentation Model¶
To further improve the performance of your semantic segmentation model, you can first pretrain a DINOv2 model on unlabeled data using self-supervised learning and then fine-tune it on your segmentation dataset. This is especially useful if your dataset is only partially labeled or if you have access to a large amount of unlabeled data.
The following example shows how to pretrain and fine-tune the model: pretrain with
pretrain, then pass the pretrained weights to
fine-tuning through the
backbone_weights key of
model_args. Check out the page on
DINOv2 to learn more about pretraining DINOv2 models on unlabeled
data.
import lightly_train
if __name__ == "__main__":
# Pretrain a DINOv2 model.
lightly_train.pretrain(
out="out/my_pretrain_experiment",
data="my_pretrain_data_dir",
model="dinov2/vitl14",
method="dinov2",
)
# Fine-tune the DINOv2 model for semantic segmentation.
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov2/vitl14-eomt",
model_args={
# Path to your pretrained DINOv2 model.
"backbone_weights": "out/my_pretrain_experiment/exported_models/exported_best.pt",
},
data={
"train": {
"images": "my_data_dir/train/images", # Path to training images
"masks": "my_data_dir/train/masks", # Path to training masks
},
"val": {
"images": "my_data_dir/val/images", # Path to validation images
"masks": "my_data_dir/val/masks", # Path to validation masks
},
"classes": { # Classes in the dataset
0: "background",
1: "car",
2: "bicycle",
# ...
},
# Optional, classes that are in the dataset but should be ignored during
# training.
"ignore_classes": [0],
},
)
Default Image Transform Arguments¶
The following are the default image transform arguments. See
transform_args and
Transforms on how to customize transform settings.
EoMT DINOv2 Default Transform Arguments
Train
{
"channel_drop": null,
"color_jitter": {
"brightness": 0.12549019607843137,
"contrast": 0.5,
"hue": 0.05,
"prob": 0.5,
"saturation": 0.5,
"strength": 1.0
},
"ignore_index": -100,
"image_size": "auto",
"normalize": "auto",
"num_channels": "auto",
"random_crop": {
"fill": 0,
"height": "auto",
"pad_if_needed": true,
"pad_position": "center",
"prob": 1.0,
"width": "auto"
},
"random_flip": {
"horizontal_prob": 0.5,
"vertical_prob": 0.0
},
"random_rotate": null,
"random_rotate_90": null,
"scale_jitter": {
"divisible_by": null,
"max_scale": 2.0,
"min_scale": 0.5,
"num_scales": 20,
"prob": 1.0,
"sizes": null,
"step_stop": null
},
"smallest_max_size": null
}
Val
{
"channel_drop": null,
"color_jitter": null,
"ignore_index": -100,
"image_size": "auto",
"normalize": "auto",
"num_channels": "auto",
"random_crop": null,
"random_flip": null,
"random_rotate": null,
"random_rotate_90": null,
"scale_jitter": null,
"smallest_max_size": {
"max_size": "auto",
"prob": 1.0
}
}
EoMT DINOv3 Default Transform Arguments
Train
{
"channel_drop": null,
"color_jitter": {
"brightness": 0.12549019607843137,
"contrast": 0.5,
"hue": 0.05,
"prob": 0.5,
"saturation": 0.5,
"strength": 1.0
},
"ignore_index": -100,
"image_size": "auto",
"normalize": "auto",
"num_channels": "auto",
"random_crop": {
"fill": 0,
"height": "auto",
"pad_if_needed": true,
"pad_position": "center",
"prob": 1.0,
"width": "auto"
},
"random_flip": {
"horizontal_prob": 0.5,
"vertical_prob": 0.0
},
"random_rotate": null,
"random_rotate_90": null,
"scale_jitter": {
"divisible_by": null,
"max_scale": 2.0,
"min_scale": 0.5,
"num_scales": 20,
"prob": 1.0,
"sizes": null,
"step_stop": null
},
"smallest_max_size": null
}
Val
{
"channel_drop": null,
"color_jitter": null,
"ignore_index": -100,
"image_size": "auto",
"normalize": "auto",
"num_channels": "auto",
"random_crop": null,
"random_flip": null,
"random_rotate": null,
"random_rotate_90": null,
"scale_jitter": null,
"smallest_max_size": {
"max_size": "auto",
"prob": 1.0
}
}
Exporting a Checkpoint to ONNX¶
Open Neural Network Exchange (ONNX) is a standard format for representing machine learning models in a framework independent manner. In particular, it is useful for deploying our models on edge devices where PyTorch is not available.
Requirements¶
Exporting to ONNX requires some additional packages to be installed. Namely
onnxruntime if
verifyis set toTrue.onnxslim if
simplifyis set toTrue.
You can install them with:
pip install "lightly-train[onnx,onnxruntime,onnxslim]"
The following example shows how to export a previously trained model to ONNX.
import lightly_train
# Instantiate the model from a checkpoint.
model = lightly_train.load_model("out/my_experiment/exported_models/exported_best.pt")
# Export to ONNX.
model.export_onnx(
out="out/my_experiment/exported_models/model.onnx",
# precision="fp16", # Export model with FP16 weights for smaller size and faster inference.
)
See export_onnx() for all available options
when exporting to ONNX.
The following notebook shows how to export a model to ONNX in Colab:
![]()
Exporting a Checkpoint to TensorRT¶
TensorRT engines are built from an ONNX representation of the model. The
export_tensorrt method internally exports the model to ONNX (see the ONNX export
section above) before building a TensorRT
engine for fast GPU inference.
Requirements¶
TensorRT is not part of LightlyTrain’s dependencies and must be installed separately. Installation depends on your OS, Python version, GPU, and NVIDIA driver/CUDA setup. See the TensorRT documentation for more details.
On CUDA 12.x systems you can often install the Python package via:
pip install tensorrt-cu12
import lightly_train
# Instantiate the model from a checkpoint.
model = lightly_train.load_model("out/my_experiment/exported_models/exported_best.pt")
# Export to TensorRT from an ONNX file.
model.export_tensorrt(
out="out/my_experiment/exported_models/model.trt", # TensorRT engine destination.
# precision="fp16", # Export model with FP16 weights for smaller size and faster inference.
)
See export_tensorrt() for all available
options when exporting to TensorRT.
You can also learn more about exporting EoMT to TensorRT using our Colab notebook:
![]()