Active Learning
Warning
The Docker Archive documentation is deprecated
The old workflow described in these docs will not be supported with new Lightly Worker versions above 2.6. Please switch to our new documentation page instead.
Lightly makes use of active learning scores to select the samples which will yield the biggest improvements of your machine learning model. The scores are calculated on-the-fly based on model predictions and provide the selection algorithm with feedback about the uncertainty of the model for the given sample.
Note
Note that the active learning features require a minimum Lightly Worker of version 2.2. You can check your installed version of the Lightly Worker by running the Sanity Check.
Prerequisites
In order to do active learning with Lightly, you will need the following things:
The installed Lightly docker (see Setup)
A dataset with a configured datasource (see Process new data in your bucket using a datapool)
Your predictions uploaded to the datasource (see Add Predictions to a Datasource)
Note
The dataset does not need to be new! For example, an initial selection without active learning can be used to train a model. The predictions from this model can then be used to improve your dataset by adding new images to it through active learning.
Selection
Once you have everything set up as described above, you can do an active learning iteration by specifying the following three things in your Lightly docker config:
method
active_learning.task_name
active_learning.score_name
Here’s an example of how to configure an active learning run:
Trigger the Job
To trigger a new job you can click on the schedule run button on the dataset overview as shown in the screenshot below:
After clicking on the button you will see a wizard to configure the parameters for the job.
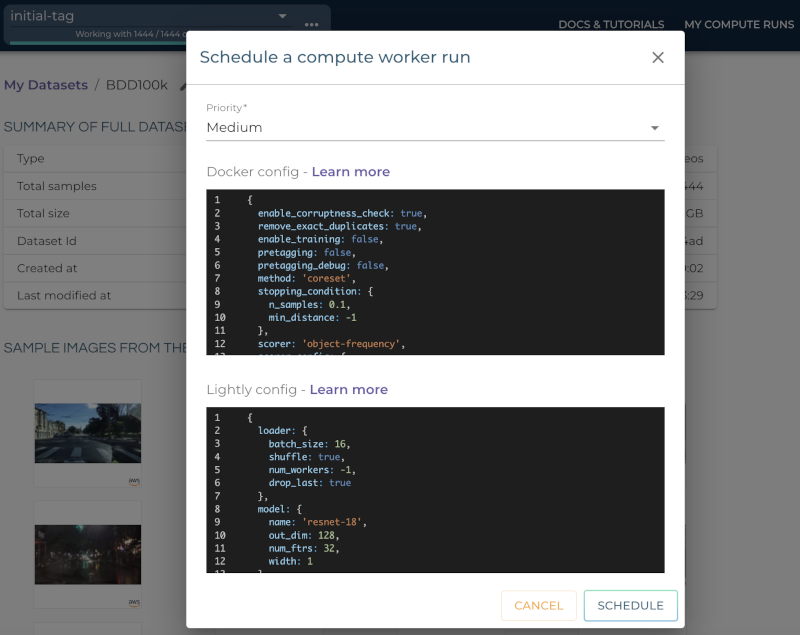
In this example we have to set the active_learning.task_name parameter in the docker config. Additionally, we set the method to coral which simultaneously considers the diversity and the active learning scores of the samples. All other settings are default values. The resulting docker config should look like this:
{
enable_corruptness_check: true,
remove_exact_duplicates: true,
enable_training: false,
pretagging: false,
pretagging_debug: false,
method: 'coral',
stopping_condition: {
n_samples: 0.1,
min_distance: -1
},
scorer: 'object-frequency',
scorer_config: {
frequency_penalty: 0.25,
min_score: 0.9
},
active_learning: {
task_name: 'my-classification-task',
score_name: 'uncertainty_margin'
}
}
The Lightly config remains unchanged.
import lightly
# Create the Lightly client to connect to the API.
client = lightly.api.ApiWorkflowClient(token="LIGHTLY_TOKEN", dataset_id="DATASET_ID")
# Schedule the docker run with
# - "active_learning.task_name" set to your task name
# - "method" set to "coral"
# All other settings are default values and we show them so you can easily edit
# the values according to your need.
client.schedule_compute_worker_run(
worker_config={
"enable_corruptness_check": True,
"remove_exact_duplicates": True,
"enable_training": False,
"pretagging": False,
"pretagging_debug": False,
"method": "coral",
"stopping_condition": {"n_samples": 0.1, "min_distance": -1},
"scorer": "object-frequency",
"scorer_config": {"frequency_penalty": 0.25, "min_score": 0.9},
"active_learning": {
"task_name": "my-classification-task",
"score_name": "uncertainty_margin",
},
},
lightly_config={
"loader": {
"batch_size": 16,
"shuffle": True,
"num_workers": -1,
"drop_last": True,
},
"model": {"name": "resnet-18", "out_dim": 128, "num_ftrs": 32, "width": 1},
"trainer": {"gpus": 1, "max_epochs": 100, "precision": 32},
"criterion": {"temperature": 0.5},
"optimizer": {"lr": 1, "weight_decay": 0.00001},
"collate": {
"input_size": 64,
"cj_prob": 0.8,
"cj_bright": 0.7,
"cj_contrast": 0.7,
"cj_sat": 0.7,
"cj_hue": 0.2,
"min_scale": 0.15,
"random_gray_scale": 0.2,
"gaussian_blur": 0.5,
"kernel_size": 0.1,
"vf_prob": 0,
"hf_prob": 0.5,
"rr_prob": 0,
},
},
)
After the worker has finished its job you can see the selected images with their active learning score in the web-app.
Active Learning with Custom Scores (not recommended as of March 2022)
Note
This is not recommended anymore as of March 2022 and will be deprecated in the future!
For running an active learning step with the Lightly docker, we need to perform 3 steps:
Create an embeddings.csv file. You can use your own models or the Lightly docker for this.
Add your active learning scores as an additional column to the embeddings file.
Use the Lightly docker to perform an active learning iteration on the scores.
Create Embeddings
You can create embeddings using your own model. Just make sure the resulting embeddings.csv file matches the required format: Create embeddings using the CLI.
Alternatively, you can run the docker as usual and as described in the First Steps section. The only difference is that you set the number of samples to be selected to 1.0, as this simply creates an embedding of the full dataset.
E.g. create and run a bash script with the following content:
# Have this in a step_1_run_docker_create_embeddings.sh
INPUT_DIR=/path/to/your/dataset
SHARED_DIR=/path/to/shared
OUTPUT_DIR=/path/to/output
LIGHTLY_TOKEN= # put your token here
N_SAMPLES=1.0
docker run --gpus all --rm -it \
-v ${INPUT_DIR}:/home/input_dir:ro \
-v ${SHARED_DIR}:/home/shared_dir:ro \
-v ${OUTPUT_DIR}:/home/output_dir \
lightly/worker:latest \
token=${LIGHTLY_TOKEN} \
lightly.loader.num_workers=4 \
stopping_condition.n_samples=${N_SAMPLES}\
method=coreset \
enable_training=True \
lightly.trainer.max_epochs=20
Running it will create a terminal output similar to the following:
[2021-09-29 13:32:11] Loading initial dataset...
[2021-09-29 13:32:11] Found 372 input images in input_dir.
[2021-09-29 13:32:11] Lightly On-Premise License is valid
[2021-09-29 13:32:11] Checking for corrupt images (disable with enable_corruptness_check=False).
Corrupt images found: 0: 100%|██████████████████| 372/372 [00:01<00:00, 310.35it/s]
[2021-09-29 13:32:14] Training self-supervised model.
GPU available: True, used: True
[2021-09-29 13:32:57,696][lightning][INFO] - GPU available: True, used: True
TPU available: None, using: 0 TPU cores
[2021-09-29 13:32:57,697][lightning][INFO] - TPU available: None, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
[2021-09-29 13:32:57,697][lightning][INFO] - LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
-----------------------------------------
0 | model | SimCLR | 11.2 M
1 | criterion | NTXentLoss | 0
-----------------------------------------
11.2 M Trainable params
0 Non-trainable params
[2021-09-29 13:34:29,772][lightning][INFO] - Saving latest checkpoint...
Epoch 19: 100%|████████████████████████████████| 23/23 [00:04<00:00, 5.10it/s, loss=2.52, v_num=0]
[2021-09-29 13:34:29] Embedding images.
Compute efficiency: 0.90: 100%|█████████████████████████| 24/24 [00:01<00:00, 21.85it/s]
[2021-09-29 13:34:31] Saving embeddings to output_dir/2021-09-29/13:32:11/data/embeddings.csv.
[2021-09-29 13:34:31] Unique embeddings are stored in output_dir/2021-09-29/13:32:11/data/embeddings.csv
[2021-09-29 13:34:31] Normalizing embeddings to unit length (disable with normalize_embeddings=False).
[2021-09-29 13:34:31] Normalized embeddings are stored in output_dir/2021-09-29/13:32:11/data/normalized_embeddings.csv
[2021-09-29 13:34:31] Sampling dataset with stopping condition: n_samples=372
[2021-09-29 13:34:31] Skipped sampling because the number of remaining images is smaller than the number of requested samples.
[2021-09-29 13:34:31] Writing report to output_dir/2021-09-29/13:32:11/report.pdf.
[2021-09-29 13:35:04] Writing csv with information about removed samples to output_dir/2021-09-29/13:32:11/removed_samples.csv
[2021-09-29 13:35:04] Done!
By running it, this will create an embeddings.csv file in the output directory. Locate it and save the path to it. E.g. It may be found under /path/to/output/2021-09-28/15:47:34/data/embeddings.csv
It should look similar to this:
filenames |
embedding_0 |
embedding_1 |
embedding_2 |
embedding_3 |
labels |
|---|---|---|---|---|---|
cats/0001.jpg |
0.29625183 |
0.50055015 |
0.36491454 |
0.8156051 |
0 |
dogs/0005.jpg |
0.36491454 |
0.29625183 |
0.38491454 |
0.36491454 |
1 |
cats/0014.jpg |
0.8156051 |
0.59055015 |
0.29625183 |
0.50055015 |
0 |
Add Active Learning Scores
You can use the predictions from your model as active learning scores.
Note
You can also use your own scorers. Just make sure that you get a value between 0.0 and 1.0 for each sample. A number close to 1.0 should indicate a very important sample you want to be selected with a higher probability.
We provide a simple Python script to append a list of scores to the embeddings.csv file.
# Have this in a step_2_add_al_scores.py
from typing import Iterable
import csv
import os
"""
Run your detection model here
Use the scorers offered by lightly to generate active learning scores.
"""
# Let's assume that you have one active learning score for every image.
# WARNING: The order of the scores MUST match the order of filenames
# in the embeddings.csv.
scores: Iterable[float] = # must be an iterable of floats,
# e.g. a list of float or a 1d-numpy array
# define the function to add the scores to the embeddings.csv
def add_al_scores_to_csv(
input_file_path: str, output_file_path: str,
scores: Iterable[float], column_name: str = "al_score"
):
with open(input_file_path, 'r') as read_obj:
with open(output_file_path, 'w') as write_obj:
csv_reader = csv.reader(read_obj)
csv_writer = csv.writer(write_obj)
# add the column name
first_row = next(csv_reader)
first_row.append(column_name)
csv_writer.writerow(first_row)
# add the scores
for row, score in zip(csv_reader, scores):
row.append(str(score))
csv_writer.writerow(row)
# use the function
# adapt the following line to use the correct path to the embeddings.csv
input_embeddings_csv = '/path/to/output/2021-07-28/12:00:00/data/embeddings.csv'
output_embeddings_csv = input_embeddings_csv.replace('.csv', '_al.csv')
add_al_scores_to_csv(input_embeddings_csv, output_embeddings_csv, scores)
print("Use the following path to the embeddings_al.csv in the next step:")
print(output_embeddings_csv)
Running it will create a terminal output similar to the following:
(base) user@machine:~/GitHub/playground/docker_with_al$ sudo python3 step_2_add_al_scores.py
Use the following path to the embedding.csv in the next step:
/path/to/output/2021-07-28/12:00:00/data/embeddings_al.csv
Your embeddings_al.csv should look similar to this:
filenames |
embedding_0 |
embedding_1 |
embedding_2 |
embedding_3 |
labels |
al_score |
|---|---|---|---|---|---|---|
cats/0001.jpg |
0.29625183 |
0.50055015 |
0.36491454 |
0.8156051 |
0 |
0.7231 |
dogs/0005.jpg |
0.36491454 |
0.29625183 |
0.38491454 |
0.36491454 |
1 |
0.91941 |
cats/0014.jpg |
0.8156051 |
0.59055015 |
0.29625183 |
0.50055015 |
0 |
0.01422 |
Run Active Learning using the Docker
At this point you should have an embeddings.csv file with the active learning scores in a column named al_scores.
We can now perform an active learning iteration using the coral selection strategy. In order to do the selection on the embeddings.csv file we need to make this file accessible to the docker. We can do this by using the shared_dir feature of the docker as described in Selecting from Embeddings File.
E.g. use the following bash script.
#!/bin/bash -e
# Have this in a step_3_run_docker_coral.sh
INPUT_DIR=/path/to/your/dataset/
SHARED_DIR=/path/to/shared/
OUTPUT_DIR=/path/to/output/
EMBEDDING_FILE= # insert the path printed in the last step here.
# e.g. /path/to/output/2021-07-28/12:00:00/data/embeddings_al.csv
cp INPUT_EMBEDDING_FILE SHARED_DIR # copy the embedding file to the shared directory
EMBEDDINGS_REL_TO_SHARED=embeddings_al.csv
LIGHTLY_TOKEN= # put your token here
N_SAMPLES= # Choose how many samples you want to use here, e.g. 0.1 for 10 percent.
docker run --gpus all --rm -it \
-v ${INPUT_DIR}:/home/input_dir:ro \
-v ${SHARED_DIR}:/home/shared_dir:ro \
-v ${OUTPUT_DIR}:/home/output_dir \
lightly/worker:latest \
token=${LIGHTLY_TOKEN} \
lightly.loader.num_workers=4 \
stopping_condition.n_samples=${N_SAMPLES}\
method=coral \
enable_training=False \
dump_dataset=True \
upload_dataset=False \
embeddings=${EMBEDDINGS_REL_TO_SHARED} \
active_learning_score_column_name="al_score" \
scorer=""
Your terminal output should look similar to this:
[2021-09-29 09:36:27] Loading initial embedding file...
[2021-09-29 09:36:27] Output images will not be resized.
[2021-09-29 09:36:27] Found 372 input images in shared_dir/embeddings_al.csv.
[2021-09-29 09:36:27] Lightly On-Premise License is valid
[2021-09-29 09:36:28] Removing exact duplicates (disable with remove_exact_duplicates=False).
[2021-09-29 09:36:28] Found 0 exact duplicates.
[2021-09-29 09:36:28] Unique embeddings are stored in shared_dir/embeddings_al.csv
[2021-09-29 09:36:28] Normalizing embeddings to unit length (disable with normalize_embeddings=False).
[2021-09-29 09:36:28] Normalized embeddings are stored in output_dir/2021-09-29/09:36:27/data/normalized_embeddings.csv
[2021-09-29 09:36:28] Sampling dataset with stopping condition: n_samples=10
[2021-09-29 09:36:28] Sampled 10 images.
[2021-09-29 09:36:28] Writing report to output_dir/2021-09-29/09:36:27/report.pdf.
[2021-09-29 09:36:56] Writing csv with information about removed samples to output_dir/2021-09-29/09:36:27/removed_samples.csv
[2021-09-29 09:36:56] Done!