Main Concepts
Self-Supervised Learning
The figure below shows an overview of the different concepts used by the LightlySSL package and a schema of how they interact. The expressions in bold are explained further below.
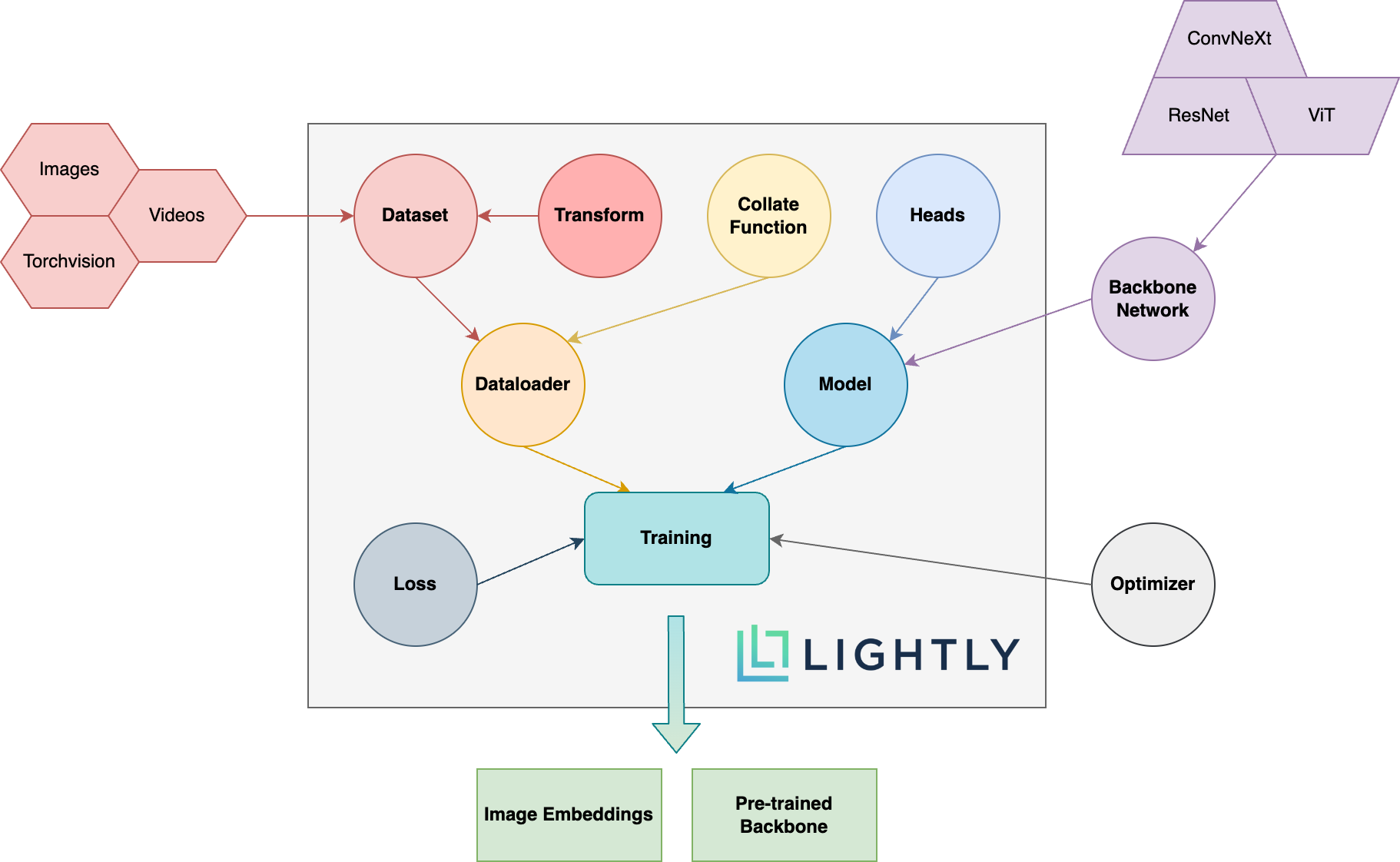
Overview of the different concepts used by the LightlySSL package and how they interact.
- Dataset
In LightlySSL, datasets are accessed through
LightlyDataset. You can create aLightlyDatasetfrom a directory of images or videos, or directly from a torchvision dataset. You can learn more about this in our tutorial:
- Transform
In self-supervised learning, the input images are often randomly transformed into views of the orignal images. The views and their underlying transforms are important as they define the properties of the model and the image embeddings. You can either use our pre-defined
transformsor write your own. For more information, check out the following pages:
- Collate Function
The collate function aggregates the views of multiple images into a single batch. You can use the default collate function. LightlySSL also provides a
MultiViewCollate
- Dataloader
For the dataloader you can simply use a PyTorch dataloader. Be sure to pass it a
LightlyDatasetthough!
- Backbone Neural Network
One of the cool things about self-supervised learning is that you can pre-train your neural networks without the need for annotated data. You can plugin whatever backbone you want! If you don’t know where to start, have a look at our SimCLR example on how to use a ResNet backbone or MSN for a Vision Transformer backbone.
- Heads
The heads are the last layers of the neural network and added on top of the backbone. They project the outputs of the backbone, commonly called embeddings, representations, or features, into a new space in which the loss is calculated. This has been found to be hugely beneficial instead of directly calculating the loss on the embeddings. LightlySSL provides common
headsthat can be added to any backbone.
- Model
The model combines your backbone neural network with one or multiple heads and, if required, a momentum encoder to provide an easy-to-use interface to the most popular self-supervised learning models. Our models page contains a large number of example implementations. You can also head over to one of our tutorials if you want to learn more about models and how to use them:
- Loss
The loss function plays a crucial role in self-supervised learning. LightlySSL provides common loss functions in the
lossmodule.
- Optimizer
With LightlySSL, you can use any PyTorch optimizer to train your model.
- Training
The model can either be trained using a plain PyTorch training loop or with a dedicated framework such as PyTorch Lightning. LightlySSL lets you choose what is best for you. Check out our models and tutorials sections on how to train models with PyTorch or PyTorch Lightning.
- Image Embeddings
During the training process, the model learns to create compact embeddings from images. The embeddings, also often called representations or features, can then be used for tasks such as identifying similar images or creating a diverse subset from your data:
- Pre-Trained Backbone
The backbone can be reused after self-supervised training. It can be transferred to any other task that requires a similar network architecture, including image classification, object detection, and segmentation tasks. You can learn more in our object detection tutorial: