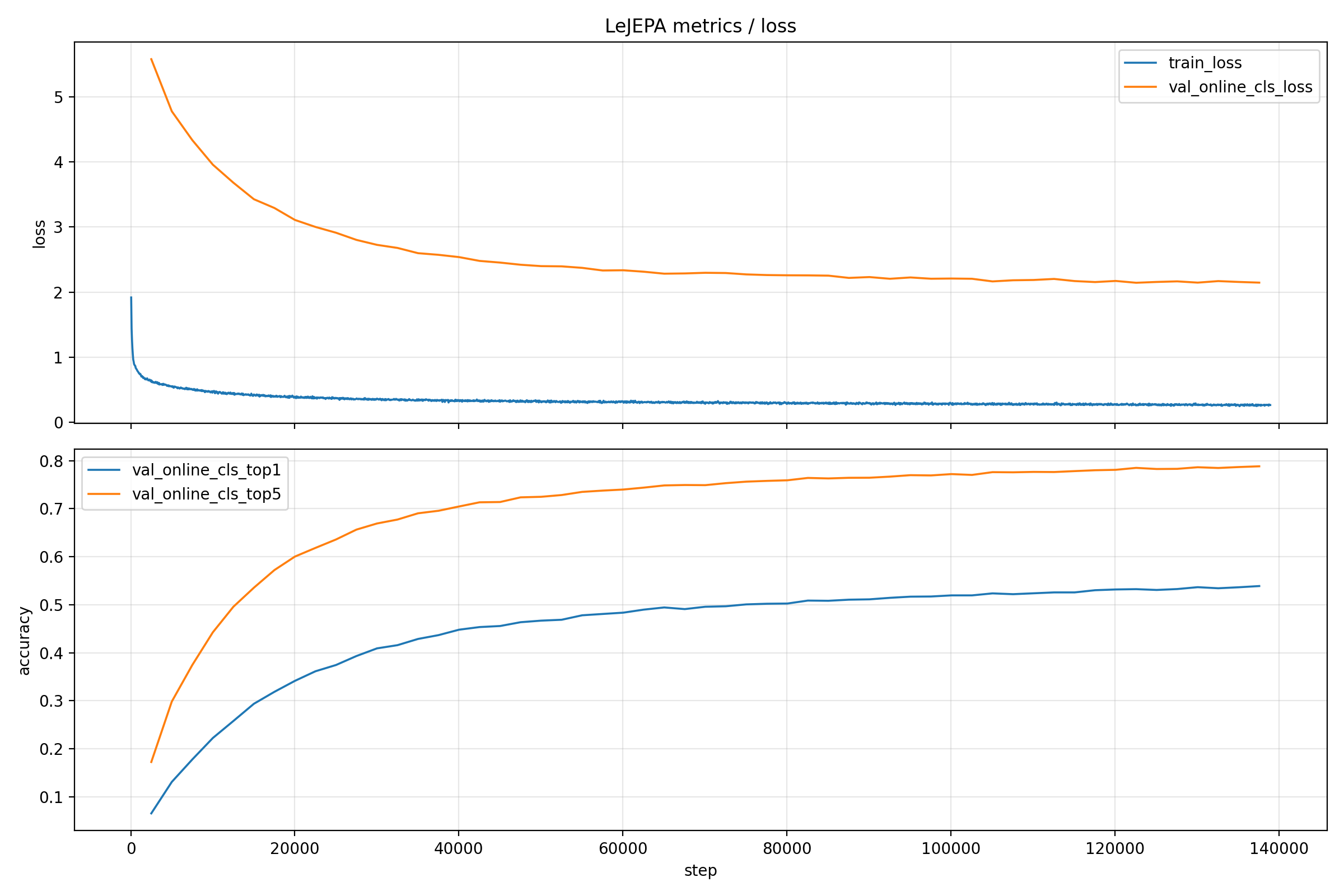
Benchmarks
Implemented models and their performance on various datasets. Hyperparameters are not tuned for maximum accuracy.
List of available benchmarks:
ImageNet1k
The following experiments have been conducted on a system with 2x4090 GPUs. Training a model takes around four days for 100 epochs (35 min per epoch), including kNN, linear probing, and fine-tuning evaluation.
Evaluation settings are based on the following papers:
Model |
Backbone |
Batch Size |
Epochs |
Linear Top1 |
Linear Top5 |
Finetune Top1 |
Finetune Top5 |
kNN Top1 |
kNN Top5 |
Tensorboard |
Checkpoint |
|---|---|---|---|---|---|---|---|---|---|---|---|
BarlowTwins |
Res50 |
256 |
100 |
62.9 |
84.3 |
72.6 |
90.9 |
45.6 |
73.9 |
||
BYOL |
Res50 |
256 |
100 |
62.5 |
85.0 |
74.5 |
92.0 |
46.0 |
74.8 |
||
DINO |
Res50 |
128 |
100 |
68.2 |
87.9 |
72.5 |
90.8 |
49.9 |
78.7 |
||
DINO |
ViT-S/16 |
128 |
100 |
73.3 |
91.3 |
79.8 |
95.0 |
67.5 |
89.7 |
||
iBOT |
ViT-S/16 |
128 |
100 |
72.2 |
90.5 |
78.3 |
94.3 |
65.4 |
88.5 |
||
LeJEPA |
ViT-S/16 |
512 |
100 |
64.0 |
85.8 |
78.7 |
94.5 |
47.1 |
74.3 |
||
MAE |
ViT-B/16 |
256 |
100 |
46.0 |
70.2 |
81.3 |
95.5 |
11.2 |
24.5 |
||
MoCoV2 |
Res50 |
256 |
100 |
61.5 |
84.1 |
74.3 |
91.9 |
41.8 |
72.2 |
||
SimCLR* |
Res50 |
256 |
100 |
63.2 |
85.2 |
73.9 |
91.9 |
44.8 |
73.9 |
||
SimCLR* + DCL |
Res50 |
256 |
100 |
65.1 |
86.2 |
73.5 |
91.7 |
49.6 |
77.5 |
||
SimCLR* + DCLW |
Res50 |
256 |
100 |
64.5 |
86.0 |
73.2 |
91.5 |
48.5 |
76.8 |
||
SwAV |
Res50 |
256 |
100 |
67.2 |
88.1 |
75.4 |
92.7 |
49.5 |
78.6 |
||
TiCo |
Res50 |
256 |
100 |
49.7 |
74.4 |
72.7 |
90.9 |
26.6 |
53.6 |
||
VICReg |
Res50 |
256 |
100 |
63.0 |
85.4 |
73.7 |
91.9 |
46.3 |
75.2 |
{kind=link}
*We use square root learning rate scaling instead of linear scaling as it yields better results for smaller batch sizes. See Appendix B.1 in the SimCLR paper.
Found a missing model? Track the progress of our planned benchmarks on GitHub.
ImageNet100
Imagenet100 is a subset of the popular ImageNet1k dataset. It consists of 100 classes with 1300 training and 50 validation images per class. We train the self-supervised models from scratch on the training data. At the end of every epoch we embed all training images and use the features for a kNN classifier with k=20 on the test set. The reported kNN Top 1 is the max accuracy over all epochs the model reached. All experiments use the same ResNet-18 backbone and the default ImageNet1k training parameters from the respective papers.
The following experiments have been conducted on a system with single A6000 GPU. Training a model takes between 20 and 30 hours, including kNN evaluation.
Model |
Backbone |
Batch Size |
Epochs |
kNN Top 1 |
Runtime |
GPU Memory |
|---|---|---|---|---|---|---|
BarlowTwins |
Res18 |
256 |
200 |
0.465 |
1319.3 Min |
11.3 GByte |
BYOL |
Res18 |
256 |
200 |
0.439 |
1315.4 Min |
12.9 GByte |
DINO |
Res18 |
256 |
200 |
0.518 |
1868.5 Min |
17.4 GByte |
FastSiam |
Res18 |
256 |
200 |
0.559 |
1856.2 Min |
22.0 GByte |
Moco |
Res18 |
256 |
200 |
0.560 |
1314.2 Min |
13.1 GByte |
NNCLR |
Res18 |
256 |
200 |
0.453 |
1198.6 Min |
11.8 GByte |
SimCLR |
Res18 |
256 |
200 |
0.469 |
1207.7 Min |
11.3 GByte |
SimSiam |
Res18 |
256 |
200 |
0.534 |
1175.0 Min |
11.1 GByte |
SwaV |
Res18 |
256 |
200 |
0.678 |
1569.2 Min |
16.9 GByte |
Imagenette
Imagenette is a subset of 10 easily classified classes from ImageNet. For our benchmarks we use the 160px version of the Imagenette dataset and resize the input images to 128 pixels during training. We train the self-supervised models from scratch on the training data. At the end of every epoch we embed all training images and use the features for a kNN classifier with k=20 on the test set. The reported kNN Top 1 is the max accuracy over all epochs the model reached. All experiments use the same ResNet-18 backbone and the default ImageNet1k training parameters from the respective papers.
The following experiments have been conducted on a system with single A6000 GPU. Training a model takes three to five hours, including kNN evaluation.
Model |
Backbone |
Batch Size |
Epochs |
kNN Top 1 |
Runtime |
GPU Memory |
|---|---|---|---|---|---|---|
BarlowTwins |
Res18 |
256 |
800 |
0.852 |
298.5 Min |
4.0 GByte |
BYOL |
Res18 |
256 |
800 |
0.887 |
214.8 Min |
4.3 GByte |
DCL |
Res18 |
256 |
800 |
0.861 |
189.1 Min |
3.7 GByte |
DCLW |
Res18 |
256 |
800 |
0.865 |
192.2 Min |
3.7 GByte |
DINO |
Res18 |
256 |
800 |
0.888 |
312.3 Min |
6.6 GByte |
FastSiam |
Res18 |
256 |
800 |
0.873 |
299.6 Min |
7.3 GByte |
MAE |
ViT-S |
256 |
800 |
0.610 |
248.2 Min |
4.4 GByte |
MSN |
ViT-S |
256 |
800 |
0.828 |
515.5 Min |
14.7 GByte |
Moco |
Res18 |
256 |
800 |
0.874 |
231.7 Min |
4.3 GByte |
NNCLR |
Res18 |
256 |
800 |
0.884 |
212.5 Min |
3.8 GByte |
PMSN |
ViT-S |
256 |
800 |
0.822 |
505.8 Min |
14.7 GByte |
SimCLR |
Res18 |
256 |
800 |
0.889 |
193.5 Min |
3.7 GByte |
SimMIM |
ViT-B32 |
256 |
800 |
0.343 |
446.5 Min |
9.7 GByte |
SimSiam |
Res18 |
256 |
800 |
0.872 |
206.4 Min |
3.9 GByte |
SwaV |
Res18 |
256 |
800 |
0.902 |
283.2 Min |
6.4 GByte |
SwaVQueue |
Res18 |
256 |
800 |
0.890 |
282.7 Min |
6.4 GByte |
SMoG |
Res18 |
256 |
800 |
0.788 |
232.1 Min |
2.6 GByte |
TiCo |
Res18 |
256 |
800 |
0.856 |
177.8 Min |
2.5 GByte |
VICReg |
Res18 |
256 |
800 |
0.845 |
205.6 Min |
4.0 GByte |
VICRegL |
Res18 |
256 |
800 |
0.778 |
218.7 Min |
4.0 GByte |
CIFAR-10
CIFAR-10 consists of 50k training images and 10k testing images. We train the self-supervised models from scratch on the training data. At the end of every epoch we embed all training images and use the features for a kNN classifier with k=200 on the test set. The reported kNN Top 1 is the max accuracy over all epochs the model reached. All experiments use the same ResNet-18 backbone and we disable the gaussian blur augmentation due to the small image sizes.
Note
The ResNet-18 backbone in this benchmark is slightly different from the torchvision variant as it starts with a 3x3 convolution and has no stride and no MaxPool2d. This is a typical variation used for CIFAR-10 benchmarks of SSL methods.
Model |
Backbone |
Batch Size |
Epochs |
kNN Top 1 |
Runtime |
GPU Memory |
|---|---|---|---|---|---|---|
BarlowTwins |
Res18 |
128 |
200 |
0.842 |
375.9 Min |
1.7 GByte |
BYOL |
Res18 |
128 |
200 |
0.869 |
121.9 Min |
1.6 GByte |
DCL |
Res18 |
128 |
200 |
0.844 |
102.2 Min |
1.5 GByte |
DCLW |
Res18 |
128 |
200 |
0.833 |
100.4 Min |
1.5 GByte |
DINO |
Res18 |
128 |
200 |
0.840 |
120.3 Min |
1.6 GByte |
FastSiam |
Res18 |
128 |
200 |
0.906 |
164.0 Min |
2.7 GByte |
Moco |
Res18 |
128 |
200 |
0.838 |
128.8 Min |
1.7 GByte |
NNCLR |
Res18 |
128 |
200 |
0.834 |
101.5 Min |
1.5 GByte |
SimCLR |
Res18 |
128 |
200 |
0.847 |
97.7 Min |
1.5 GByte |
SimSiam |
Res18 |
128 |
200 |
0.819 |
97.3 Min |
1.6 GByte |
SwaV |
Res18 |
128 |
200 |
0.812 |
99.6 Min |
1.5 GByte |
SMoG |
Res18 |
128 |
200 |
0.743 |
192.2 Min |
1.2 GByte |
BarlowTwins |
Res18 |
512 |
200 |
0.819 |
153.3 Min |
5.1 GByte |
BYOL |
Res18 |
512 |
200 |
0.868 |
108.3 Min |
5.6 GByte |
DCL |
Res18 |
512 |
200 |
0.840 |
88.2 Min |
4.9 GByte |
DCLW |
Res18 |
512 |
200 |
0.824 |
87.9 Min |
4.9 GByte |
DINO |
Res18 |
512 |
200 |
0.813 |
108.6 Min |
5.0 GByte |
FastSiam |
Res18 |
512 |
200 |
0.788 |
146.9 Min |
9.5 GByte |
Moco* |
Res18 |
512 |
200 |
0.847 |
112.2 Min |
5.6 GByte |
NNCLR* |
Res18 |
512 |
200 |
0.815 |
88.1 Min |
5.0 GByte |
SimCLR |
Res18 |
512 |
200 |
0.848 |
87.1 Min |
4.9 GByte |
SimSiam |
Res18 |
512 |
200 |
0.764 |
87.8 Min |
5.0 GByte |
SwaV |
Res18 |
512 |
200 |
0.842 |
88.7 Min |
4.9 GByte |
SMoG |
Res18 |
512 |
200 |
0.686 |
110.0 Min |
3.4 GByte |
BarlowTwins |
Res18 |
512 |
800 |
0.859 |
517.5 Min |
7.9 GByte |
BYOL |
Res18 |
512 |
800 |
0.910 |
400.9 Min |
5.4 GByte |
DCL |
Res18 |
512 |
800 |
0.874 |
334.6 Min |
4.9 GByte |
DCLW |
Res18 |
512 |
800 |
0.871 |
333.3 Min |
4.9 GByte |
DINO |
Res18 |
512 |
800 |
0.848 |
405.2 Min |
5.0 GByte |
FastSiam |
Res18 |
512 |
800 |
0.902 |
582.0 Min |
9.5 GByte |
Moco* |
Res18 |
512 |
800 |
0.899 |
417.8 Min |
5.4 GByte |
NNCLR* |
Res18 |
512 |
800 |
0.892 |
335.0 Min |
5.0 GByte |
SimCLR |
Res18 |
512 |
800 |
0.879 |
331.1 Min |
4.9 GByte |
SimSiam |
Res18 |
512 |
800 |
0.904 |
333.7 Min |
5.1 GByte |
SwaV |
Res18 |
512 |
800 |
0.884 |
330.5 Min |
5.0 GByte |
SMoG |
Res18 |
512 |
800 |
0.800 |
415.6 Min |
3.2 GByte |
*Increased size of memory bank from 4096 to 8192 to avoid changing the memory bank too quickly due to larger batch size.
We make the following observations running the benchmark:
Self-Supervised models benefit from larger batch sizes and longer training.
Training time is roughly the same for all methods (three to four hours for 200 epochs).
Memory consumption is roughly the same for all methods.
MoCo and SwaV learn quickly in the beginning and then plateau.
SimSiam or NNCLR take longer to warm up but then catch up when training for 800 epochs.
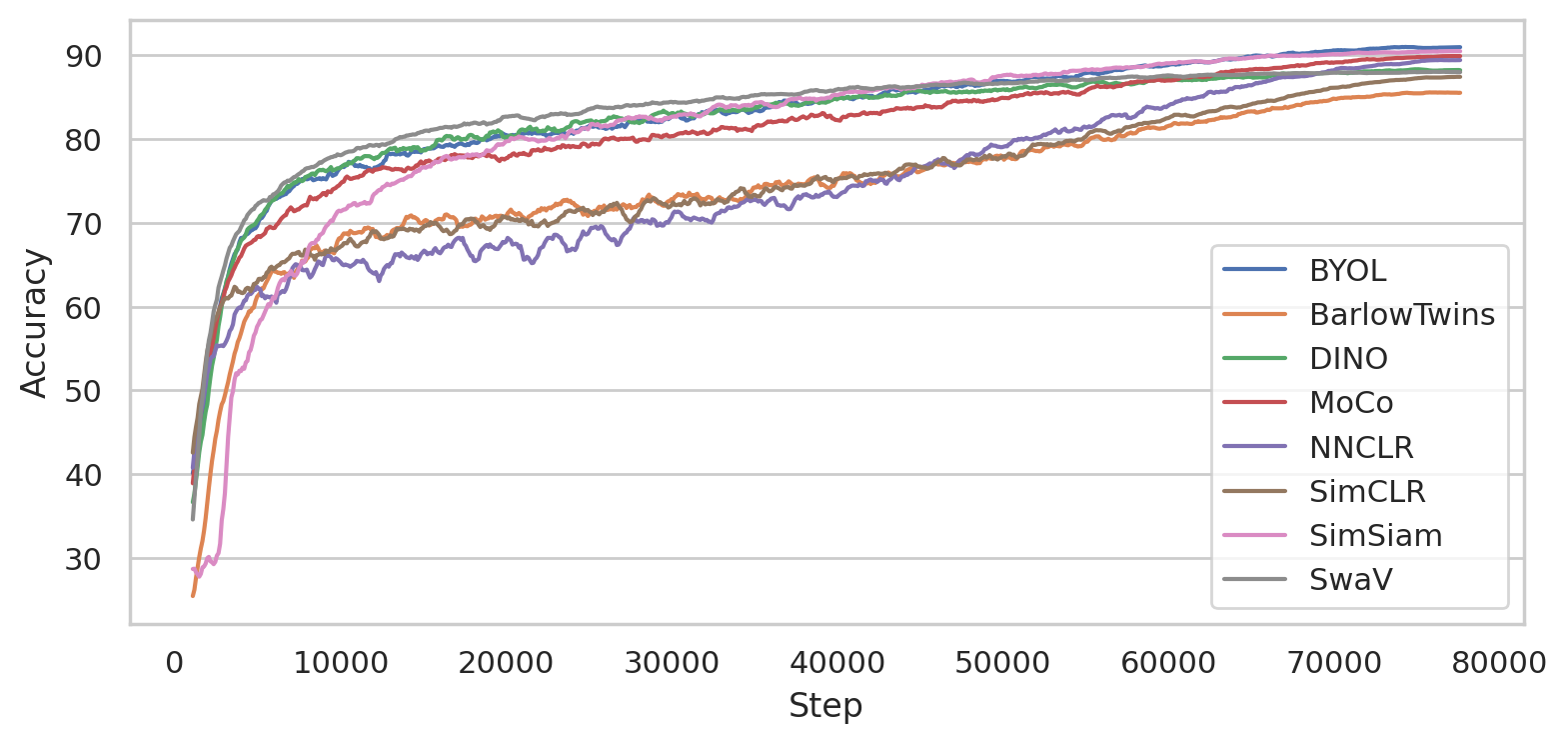
kNN accuracy on test set of models trained for 800 epochs with batch size 512.
Interactive plots of the 800 epoch accuracy and training loss are hosted on tensorboard.