
Security
Security and data privacy are very important to us at Lightly. In this section you find all security related information. Legal documents such as Privacy Notice, T&C, and DPA are available under https://lightly.ai/legal.
LightlyOne has been designed with data security in mind from the beginning. Here are the most important points:
- Everything that is transmitted to and from our API is encrypted and secured using HTTPS.
- Data always stays with the user. We neither copy, store, nor process data outside of the LightlyOne Worker, which runs on your own infrastructure.
- You can control who has access to your datasets using our Role Based Access Model.

Architecture Overview
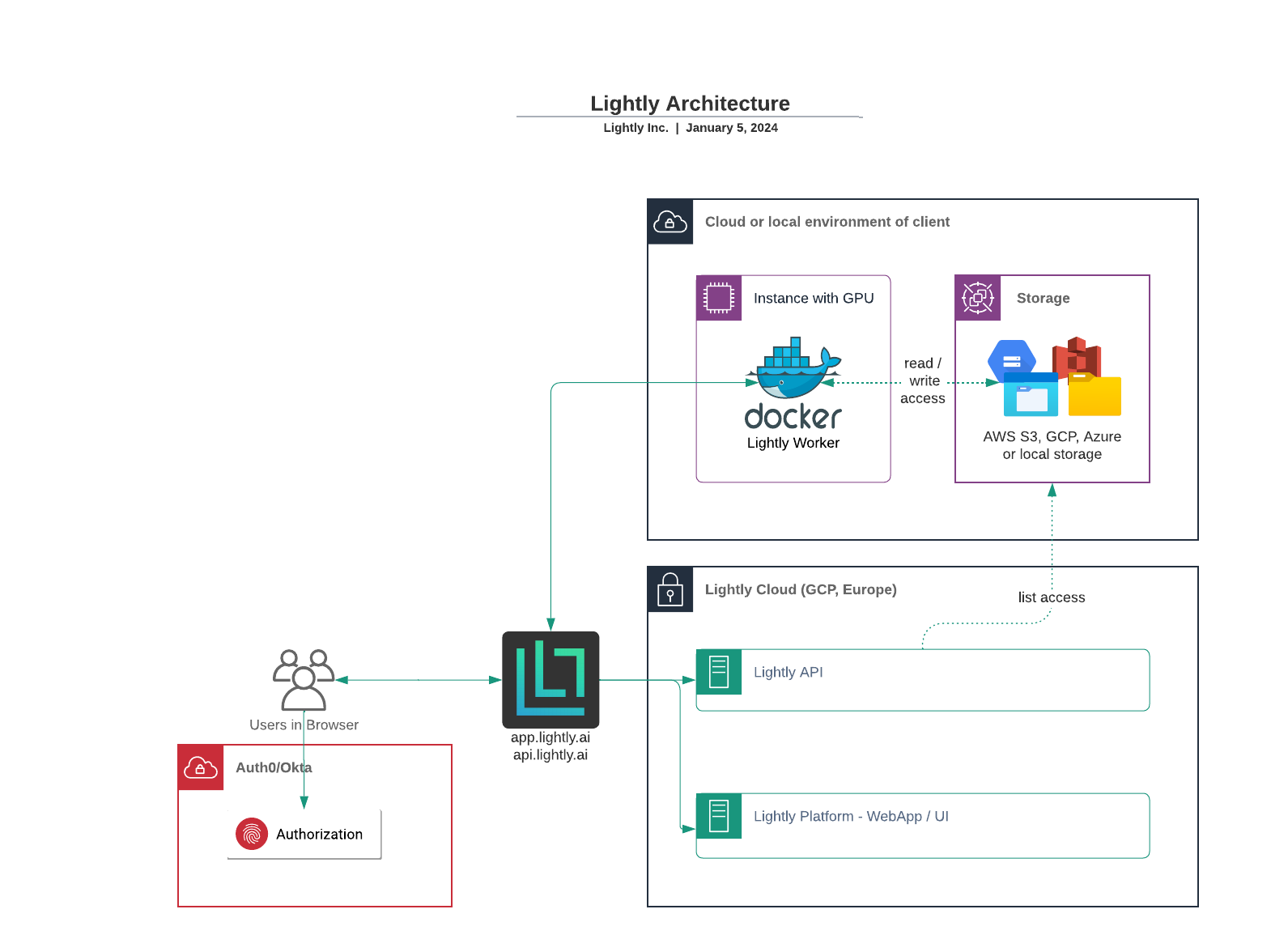
The following diagram shows how the different components are connected.
- The LightlyOne hosted API only has access to "list" which files are in the datasource and therefore only sees filenames. This permission is required for licensing and more advanced features, such as the datapool.
- All processing of sensitive data (PII) happens in the LightlyOne Worker within your environment.
- Make sure that the LightlyOne Worker has access to https://api.lightly.ai to communicate with the API.
How does your Data Flow Around?
We differentiate between usage data and the actual raw unlabeled data stored in your cloud storage. Samples can be images or videos and their subtypes, such as sequences, frames, thumbnails, or object crops. Samples typically contain sensitive information (PII). We set up the whole Lightly cloud architecture in a way that you can fully restrict sensitive data from leaving your cloud environment (see AWS S3).
Whenever you process new data using LightlyOne, the following steps happen:
- You create a new run using the Lightly Python Client. The run contains information about the location of the data (bucket path to AWS S3, Google Cloud Storage, Azure, or to your local storage) as well as the parameters of how the data should be processed.
- After the run has been created, the LightlyOne Worker can process it. The LightlyOne Worker typically runs on a GPU instance within your own cloud environment or on-premise. It uses the run information to load the data directly from your storage securely by using signed URLs created by the LightlyOne Platform.
- At the end of the run, the LightlyOne Worker pushes part of the results from the selection to the LightlyOne Platform. The LightlyOne Platform only receives non-sensitive information such as which filenames have been selected, the embeddings, the metadata, and predictions. Other assets created of the results by the LightlyOne Worker, such as thumbnails and frames that could contain sensitive information, are stored in your own cloud or local storage.
This setup has several advantages:
- The large amount of data that could contain thousands of videos or millions of frames is only moved around within your cloud infrastructure when needed. If the data in your cloud storage is in the same region as your instance, no egress traffic cost occurs, and the latency is very low for fast processing.
- LightlyOne never stores sensitive (PII) information, so you don’t have to worry about this.
- This setup allows for additional hardening of the access rules/permission policy as the LightlyOne Cloud does not need to read the actual data in your bucket (see more restrictive policies with AWS S3).
Where is your Data Stored?
Data stored within the LightlyOne Platform (does not contain PII or sensitive data):
- Embeddings - encoded vector representation describing images that
- Metadata - any metadata provided to the data selection workflow is cached for faster access and visualization in the user interface.
- Predictions - similar to metadata, predictions are cached as well.
Data stored within your own local or cloud infrastructure (contains PII or sensitive data):
- Samples - the actual images and videos.
- extracted crops, frames, and thumbnails.
- Artifacts with sensitive information such as report.pdf
Updated 8 months ago