
Use Similarity Search to Find Similar Samples
Use this complete guide to perform a similarity search with LightlyOne to find and select similar data.
This tutorial will teach you how to perform a similarity search with LightlyOne. You will work on the results acquired from your previous run with the Comma10k dataset. With similarity search, it's easier to find out data points similar to the ones with which your model did not perform well. You can then focus on annotations of these data points and improve your model.
Why should I use similarity search?
Imagine that your model has decent performance overall. You notice that it does not work well with some specific input samples, e.g., certain types of vehicles, and you want to analyze them. Or, you might simply find some samples curious, and you want to investigate similar samples in your dataset. Similarity search is the right tool for this kind of need.
Prerequisites
This tutorial follows the results from Active Learning Using YOLOv7 and Comma10k.
You will need the following things:
- A previous dataset and run created in Active Learning Using YOLOv7 and Comma10k.
- Access to a cloud bucket to which you can upload your dataset. The following tutorial will use an AWS S3 bucket.
Tag samples in dataset
Similarity search is based on data tags. Query images are recognized by tags and then loaded by the LightlyOne Worker. To create a tag, you can select samples with the LightlyOne Platform, as introduced in Create a Tag, or do it through the Lightly Python Client if you already know the names of the sample files. The following code snippet demonstrates how to tag certain input files:
from lightly.api import ApiWorkflowClient
# Create the Lightly client to connect to the API.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN", dataset_id="MY_DATASET_ID")
filenames = ["file1.png", "file2.png"]
tag = client.create_tag_from_filenames(
fnames_new_tag=filenames,
new_tag_name="my-new-tag"
)
print(tag)
# {"id": "..."}Then you can see the tagged samples in the LightlyOne Platform. For instance, here are 5 images from the Comma10k dataset tagged as curious-samples.
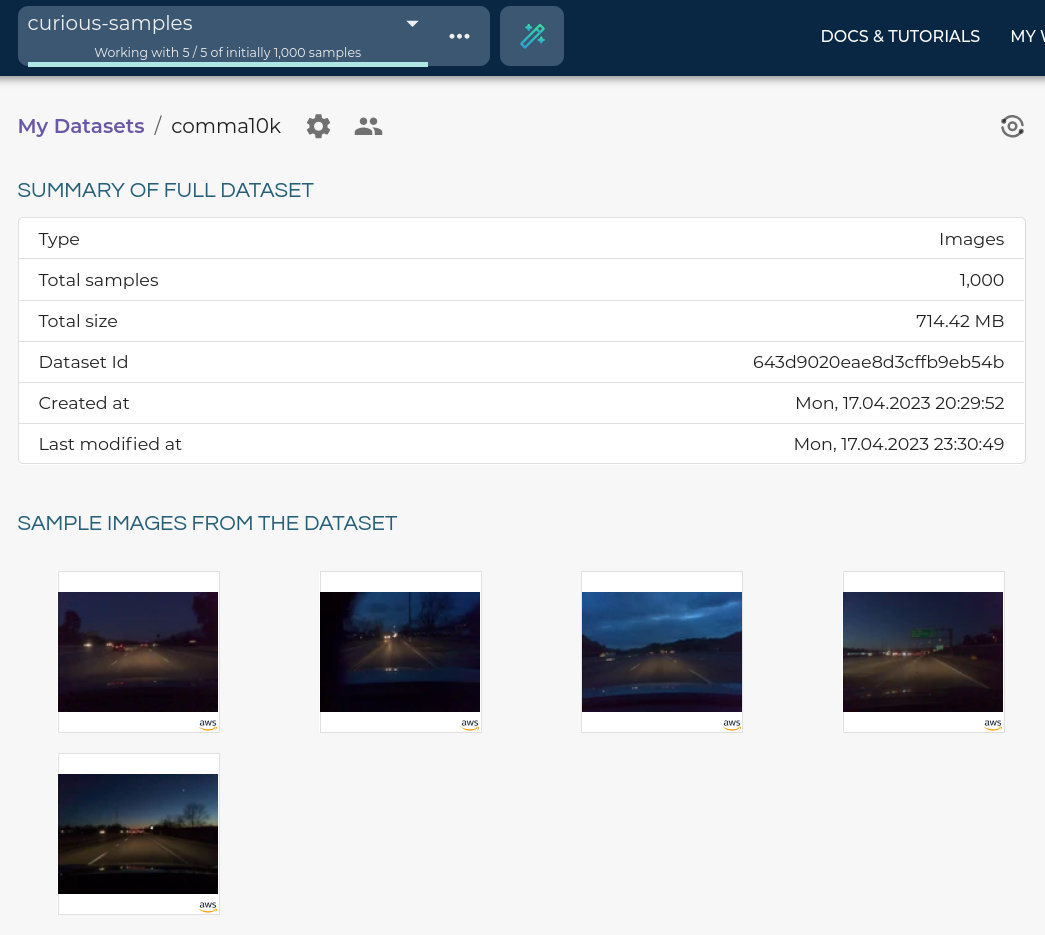
Query images to be used for similarity search.
Perform similarity search
To perform a similarity search on the input dataset, the selection strategy should be set as SIMILARITY. The example below performs a similarity search to find 100 images in the Comma10k dataset that are the most similar to those tagged as curious-samples.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Set the destination dataset where the results will be added.
# You can also create a new dataset just for the search by running
# `client.create_dataset(dataset_name="new-dataset", dataset_type=DatasetType.IMAGES)`
# Note that the destination dataset does not to be the same as the query dataset.
client.set_dataset_id_by_name("comma10k")
# Also need to configure the Input datasource and the Lightly datasource as in
# previous tutorials.
# This example performs a search with the comma10k datasource.
client.set_s3_delegated_access_config(...)
# We want to use tagged images in the comma10k dataset as the query images.
query_dataset_id = client.get_datasets_by_name("comma10k")[0].id
# Schedule a similarity search with `curious-samples` from dataset `comma10k`
# against all images from datasource `comma10k`.
scheduled_run_id = client.schedule_compute_worker_run(
worker_config={
"datasource": {
# Need to set `process_all` to search the entire comma10k datasource.
# Otherwise, only the samples in the datasource but not in the destination
# dataset will be considered.
"process_all": True,
},
},
selection_config={
"n_samples": 100,
"strategies": [
{
"input": {
"type": "EMBEDDINGS",
"dataset_id": query_dataset_id,
"tag_name": "curious-samples",
},
"strategy": {
"type": "SIMILARITY",
},
},
],
},
lightly_config={
"loader": {"batch_size": 128},
},
)Note that the query images do not need to be from the same dataset as the destination dataset or from the same datasource. You can use tags from other datasets or datasources to search for similar images in the input data source. If the datasource is the same as the one used to create the destination dataset, the search result will be samples not yet in the destination dataset. See the appendix for examples. If you use an existing dataset as the destination dataset, samples selected in the search will have a new tag. Following this example, you will see results similar to this:
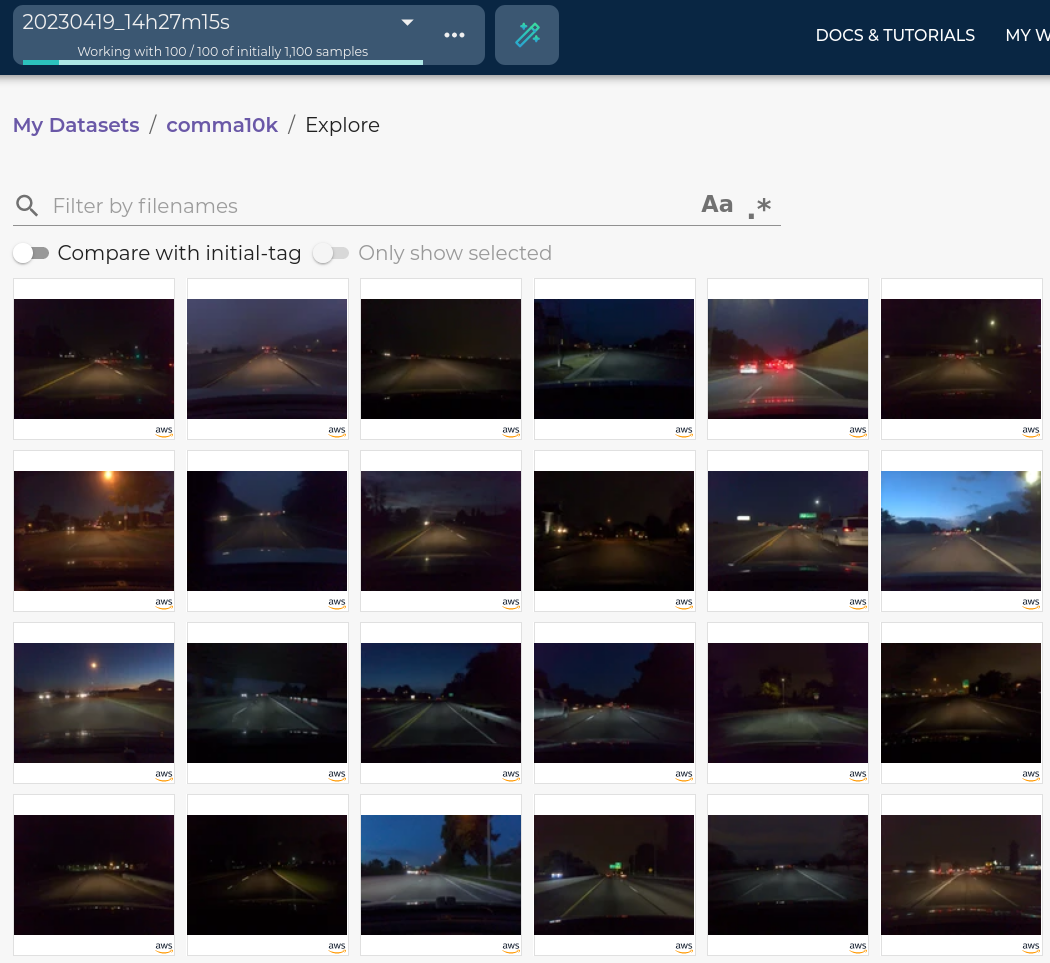
Samples selected in the search.
100 images are selected during the search and added to the destination dataset with a new tag. You can also compare the embeddings of the newly selected samples with the initially selected ones.
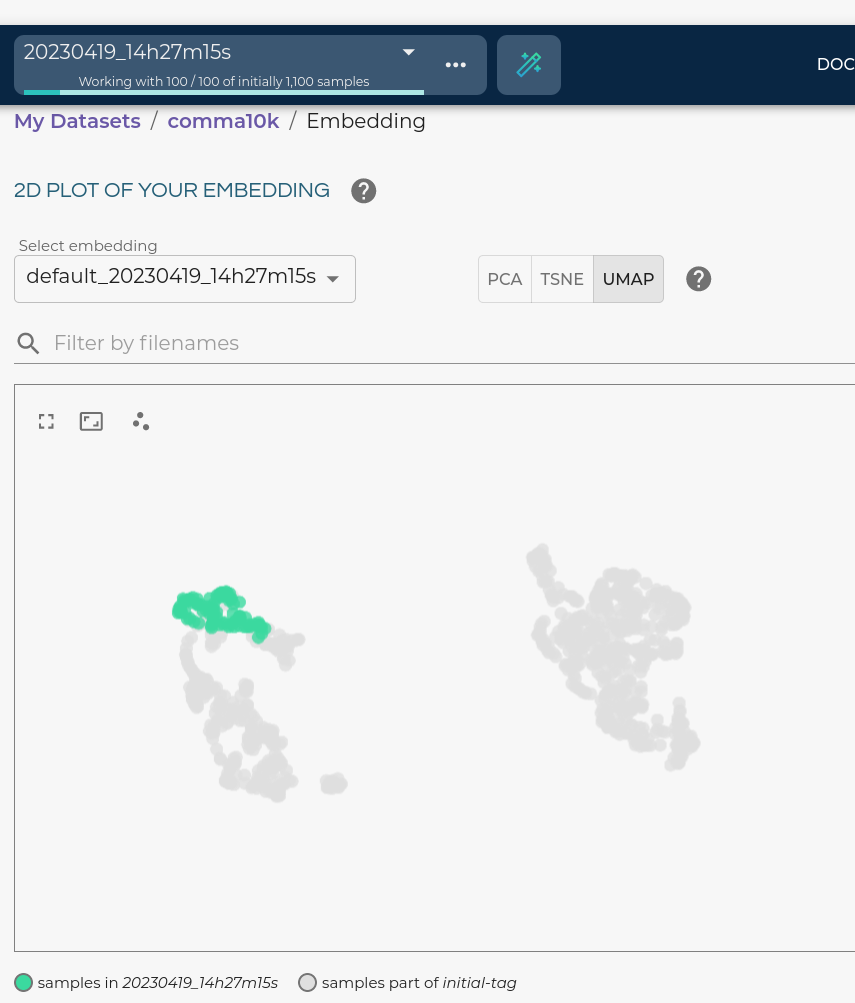
Compare embeddings of the search result and the initial samples.
Appendix
Perform similarity search when query dataset and destination dataset are different
The following example demonstrates how to use a query dataset that is different from the destination dataset, e.g., perform a similarity search with samples from an existing dataset against a newly collected dataset. For example, there are two datasets: comma10k (known dataset) and car-camera (brand new dataset). We want to use images in comma10k that are tagged as curious-samples to find similar images in car-camera.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Create a new dataset with the brand new dataset.
client.create_dataset(dataset_name="car-camera", dataset_type=DatasetType.IMAGES)
# Configure the Input datasource for the brand new dataset.
client.set_s3_delegated_access_config(
resource_path="s3://bucket/input/car-camera/",
region="eu-central-1",
role_arn="S3-ROLE-ARN",
external_id="S3-EXTERNAL-ID",
purpose=DatasourcePurpose.INPUT,
)
# Configure the Lightly datasource for the brand new dataset.
client.set_s3_delegated_access_config(
resource_path="s3://bucket/lightly/car-camera/",
region="eu-central-1",
role_arn="S3-ROLE-ARN",
external_id="S3-EXTERNAL-ID",
purpose=DatasourcePurpose.LIGHTLY,
)
# We want to use tagged images in the comma10k dataset as the query images.
query_dataset_id = client.get_datasets_by_name("comma10k")[0].id
# Schedule a similarity search with `curious-samples` from dataset `comma10k`
# against all images from datasource `car-camera`.
scheduled_run_id = client.schedule_compute_worker_run(
# No need to set `datasource.process_all = True` in worker config here because the
# dataset is brand new and all images in the datasource are fresh.
selection_config={
"n_samples": 100,
"strategies": [
{
"input": {
"type": "EMBEDDINGS",
"dataset_id": query_dataset_id,
"tag_name": "curious-samples",
},
"strategy": {
"type": "SIMILARITY",
},
},
],
},
lightly_config={
"loader": {"batch_size": 128},
},
)The result is 100 images selected from the new input datasource. They will be stored in the newly created LightlyOne dataset car-camera.
Updated 8 months ago