
Datapool
LightlyOne has been designed in a way that you can incrementally build up a dataset for your project. It automatically keeps track of the representations of previously selected samples and uses this information to pick new samples in order to maximize the quality of the final dataset. It also allows for combining two different datasets into one.
Datapool is deactivated by default but can be enabled in your worker_config when scheduling a job by setting use_datapool:True in your LightlyOne run configuration.
When Should You Use a LightlyOne Datapool?
If you want to grow an existing dataset and add additional samples to it, use the datapool.
The most common use case for this is that you want to increase your machine learning model performance by growing the labeled set. The new samples to be added to the existing dataset will consider the already selected samples in the selection process. For example, when using a diversity selection strategy, the datapool will ensure that only samples different from the already selected samples are added.
The datapool feature requires the data type (either images or videos) to stay the same.
If you want to select new samples independent of previous selections, use a new dataset instead of the datapool.
If datapool is disabled (the default), the input dataset must be completely empty. Otherwise, the LightlyOne Worker will abort the run with an error.
Working with a Datapool
For example, imagine you have a couple of raw videos. After processing them with the LightlyOne Worker once, you end up with a dataset of diverse frames in the LightlyOne Platform. Then, you add two more videos to your datasource. The new raw data might include unseen samples, which should be added to your dataset in the LightlyOne Platform. You can do this by simply rerunning the LightlyOne Worker. It will automatically find the new videos, extract the frames, and compare them to the images in the dataset on the LightlyOne Platform. The selection strategy will take the existing data in your dataset into account when selecting new data.
Number of Selected Samples
When scheduling a new run, the number of samples added to an existing datapool is determined by the n_samples and proportion_samples configuration options. Both options only take new, unprocessed data into account and are independent of the current datapool size.'n_samples': 10 selects 10 samples from the data added to the datasource since the last run and adds them to the existing datapool. Similarly, 'proportion_samples': 0.1 selects 10% of the data added to the datasource since the last run and adds them to the existing datapool.
Tags
Every run of the LightlyOne Worker creates a new tag with the samples selected by the run. The tag uses a timestamp as the name. Furthermore, there is always a tag called initial-tag, which consists of all the images in the dataset. If you do further iterations with the datapool and add new batches of data, the initial-tag will grow, whereas the new batches will be reflected by individual tags, as shown in the picture below.
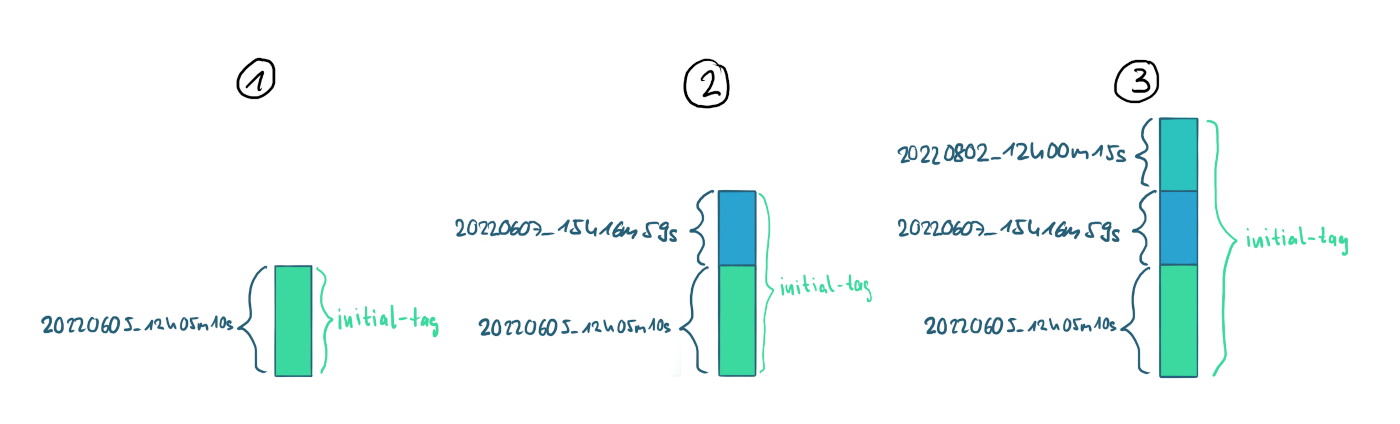
Tags from multiple LightlyOne Worker runs.
After the LightlyOne Worker run, you can go to the embedding view of the LightlyOne Platform to see the newly added samples there in a new tag. You'll see that the new samples (in green) fill some gaps left by the images in the first iteration (in grey). However, some gaps remain, which could be filled by adding more videos to the bucket and rerunning the LightlyOne Worker.

Embedding view on LightlyOne Platform with samples from the first (gray) and second (green) iteration.
You can export the filenames of all samples in a tag directly from Python code.
Export Filenames of a DatapoolIf you want to access the filenames of all samples in the datapool you can do this by exporting the
initial-tag.You can also access only the filenames of the samples selected in the last run.
This workflow of iteratively growing your dataset with the LightlyOne Worker has the following advantages:
- After each iteration, you can learn from your findings to know which raw data you need to collect next.
- Only your new data is processed, saving you time and compute cost.
- You don’t need to configure anything. Just rerun the same command.
- Only samples that differ from the existing ones are added to the dataset.
If the LightlyOne Worker does not find new samples in your datasource or there are no new samples to be added to the datapool after selection, the LightlyOne Worker will abort the run.
Report
LightlyOne Worker generates a report.pdf file after every run. The report gives further details on how many samples have been processed. The image below shows part of a report of a run with an existing datapool. Datapool Input shows that 100 samples were in the datapool before the run. Datapool Output shows that the datapool contains 150 samples after the run. The report also tells us that the 50 samples added to the datapool were selected from 2 videos that contain 3608 images/frames in total.

Information about the processed data is shown in report.pdf
Further information, such as the distance in embedding space from the newly selected samples to samples already in the datapool is shown as well:
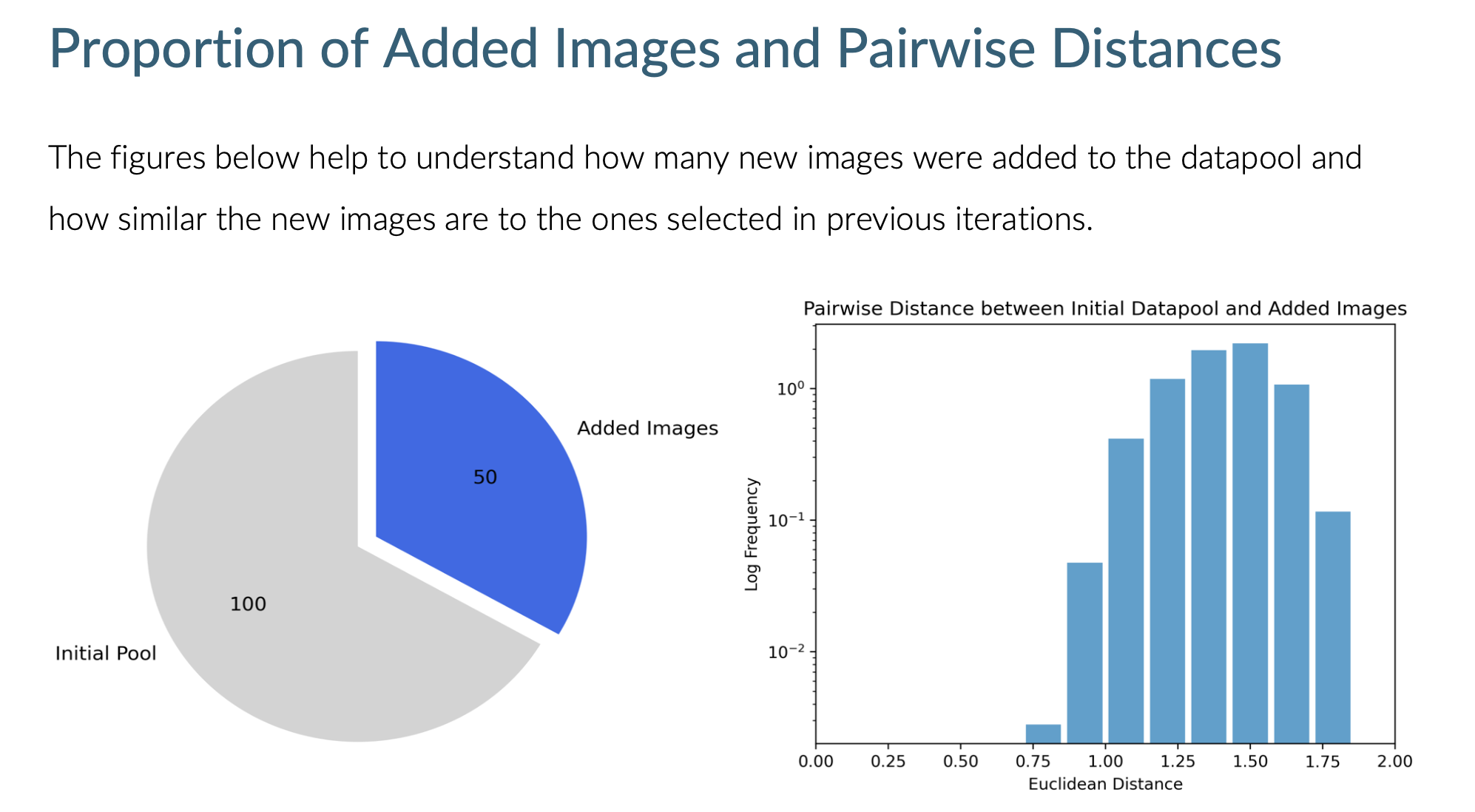
Datapool size and pairwise distance between newly and previously selected samples in the datapool.
The report also features a 2D embedding view of the datapool:
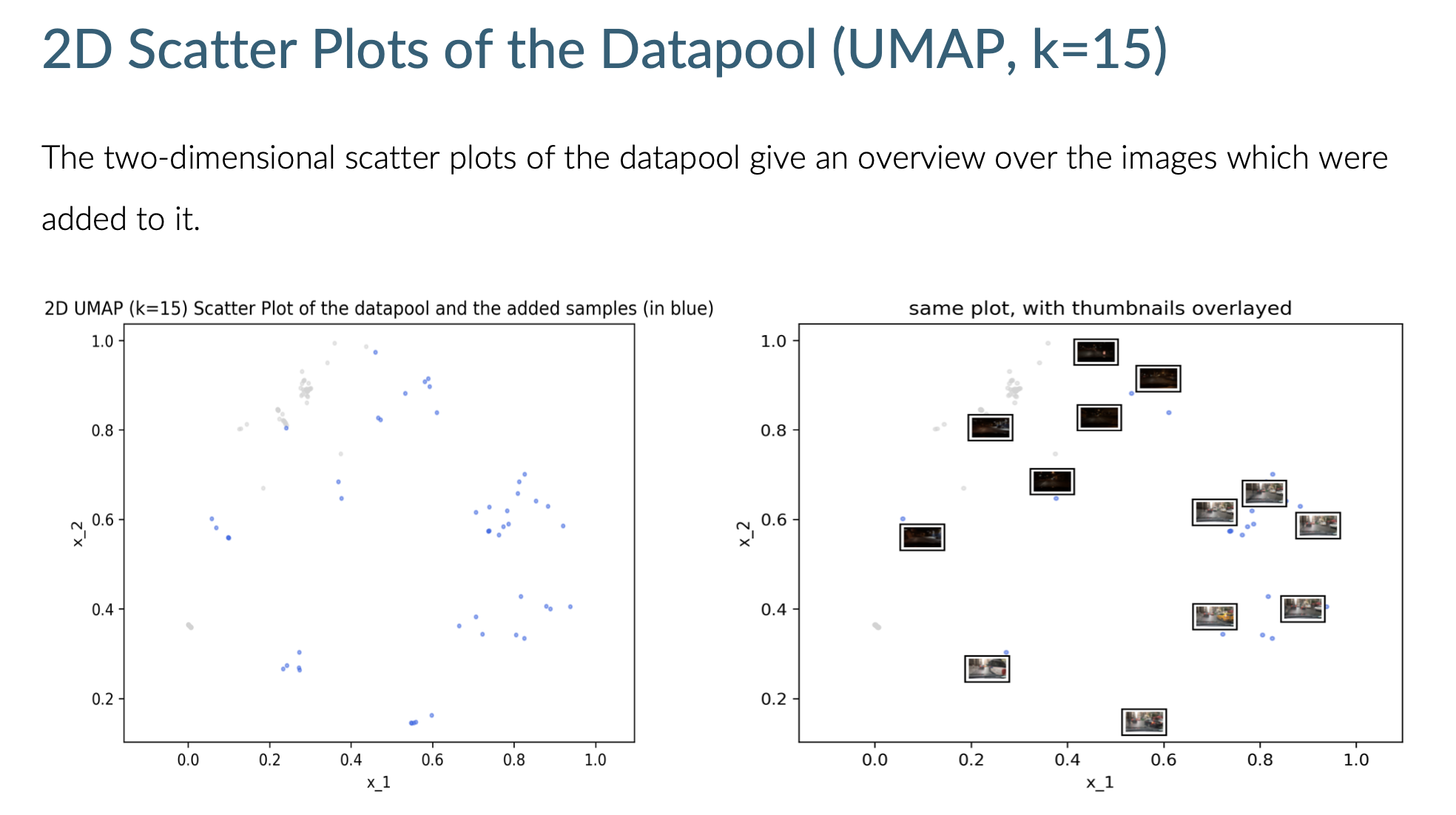
Datapool embedding view in the report. Grey and blue points are previously and newly added samples, respectively.
You can find example reports here:
A Full Example
This example covers how to:
- Schedule a run to process a storage bucket with three videos.
- Add two more videos to the same bucket.
- Run the LightlyOne Worker with the same config again to use the datapool feature.
This is the content of the storage bucket before running the LightlyOne Worker for the first time:
s3://bucket/input/project_A/videos/
├── 05009dc4-18640d99.mov
├── 05009dc4-18640d99.mov
└── 05009dc4-18640d99.movCreate a dataset which uses that bucket:
import json
from lightly.api import ApiWorkflowClient
from lightly.openapi_generated.swagger_client import DatasetType, DatasourcePurpose
# Create the LightlyOne client to connect to the API.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Create a new dataset on the LightlyOne Platform.
client.create_dataset(
dataset_name="videos-datapool",
dataset_type=DatasetType.VIDEOS,
)
# Configure the Input datasource.
client.set_s3_delegated_access_config(
resource_path="s3://bucket/input/project_A/videos/",
region="eu-central-1",
role_arn="S3-ROLE-ARN",
external_id="S3-EXTERNAL-ID",
purpose=DatasourcePurpose.INPUT,
)
# Configure the Lightly datasource.
client.set_s3_delegated_access_config(
resource_path="s3://bucket/lightly/project_A/",
region="eu-central-1",
role_arn="S3-ROLE-ARN",
external_id="S3-EXTERNAL-ID",
purpose=DatasourcePurpose.LIGHTLY,
)import json
from lightly.api import ApiWorkflowClient
from lightly.openapi_generated.swagger_client import DatasetType, DatasourcePurpose
# Create the LightlyOne client to connect to the API.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Create a new dataset on the LightlyOne Platform.
client.create_dataset(
dataset_name="pedestrian-videos-datapool",
dataset_type=DatasetType.VIDEOS,
)
# Configure the Input datasource.
client.set_s3_config(
resource_path="s3://bucket/input/project_A/videos/",
region="eu-central-1",
access_key="S3-ACCESS-KEY",
secret_access_key="S3-SECRET-ACCESS-KEY",
purpose=DatasourcePurpose.INPUT,
)
# Configure the Lightly datasource.
client.set_s3_config(
resource_path="s3://bucket/lightly/project_A/",
region="eu-central-1",
access_key="S3-ACCESS-KEY",
secret_access_key="S3-SECRET-ACCESS-KEY",
purpose=DatasourcePurpose.LIGHTLY,
)import json
from lightly.api import ApiWorkflowClient
from lightly.openapi_generated.swagger_client import DatasetType, DatasourcePurpose
# Create the LightlyOne client to connect to the API.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Create a new dataset on the LightlyOne Platform.
client.create_dataset(
dataset_name="pedestrian-videos-datapool",
dataset_type=DatasetType.VIDEOS,
)
# Configure the Input datasource.
client.set_gcs_config(
resource_path="gs://bucket/input/project_A/videos/",
project_id="PROJECT-ID",
credentials=json.dumps(json.load(open("credentials_read.json"))),
purpose=DatasourcePurpose.INPUT,
)
# Configure the Lightly datasource.
client.set_gcs_config(
resource_path="gs://bucket/lightly/project_A/",
project_id="PROJECT-ID",
credentials=json.dumps(json.load(open("credentials_write.json"))),
purpose=DatasourcePurpose.LIGHTLY,
)import json
from lightly.api import ApiWorkflowClient
from lightly.openapi_generated.swagger_client import DatasetType, DatasourcePurpose
# Create the LightlyOne client to connect to the API.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Create a new dataset on the LightlyOne Platform.
client.create_dataset(
dataset_name="pedestrian-videos-datapool",
dataset_type=DatasetType.VIDEOS,
)
# Configure the Input datasource.
client.set_azure_config(
container_name="my-container/input/project_A/videos/",
account_name="ACCOUNT-NAME",
sas_token="SAS-TOKEN",
purpose=DatasourcePurpose.INPUT,
)
# Configure the Lightly datasource.
client.set_azure_config(
container_name="my-container/lightly/project_A/",
account_name="ACCOUNT-NAME",
sas_token="SAS-TOKEN",
purpose=DatasourcePurpose.LIGHTLY,
)First Run
Now, run the following code to select a subset based on the 'n_samples': 100 stopping condition.
from lightly.api import ApiWorkflowClient
# Create the LightlyOne client to connect to the API.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Let's fetch the dataset we created above.
client.set_dataset_id_by_name(dataset_name="videos-datapool")
# Schedule the run.
client.schedule_compute_worker_run(
worker_config={
"use_datapool": True,
"enable_training": False,
},
selection_config={
"n_samples": 100,
"strategies": [
{
"input": {
"type": "EMBEDDINGS",
},
"strategy": {
"type": "DIVERSITY",
},
}
],
},
)After running the code, ensure you have a running LightlyOne Worker to process the run. If not, start the LightlyOne Worker using the following command:
docker run --shm-size="1024m" --gpus all --rm -it \
-e LIGHTLY_TOKEN="MY_LIGHTLY_TOKEN" \
-e LIGHTLY_WORKER_ID="MY_WORKER_ID" \
lightly/worker:latestAdd More Files to Bucket
After processing the initial set of videos, now add more data to the bucket. It now looks like this:
s3://bucket/input/project_A/videos/
├── 05009dc4-18640d99.mov
├── 05009dc4-18640d99.mov
├── 05009dc4-18640d99.mov
├── 0501a510-789c0ba1.mov
└── 0501cda3-5c939ca7.movSecond Run
Run the same script again (it won’t create a new dataset, but use the existing one based on the dataset name).
The Process All FlagBy default, LightlyOne Worker will only process the images that were added to the bucket after the first run. For this, LightlyOne remembers the exact time a bucket was last processed. If you want to process all images in the bucket, set the process all flag to true. You can find more information under Process All Data below.
from lightly.api import ApiWorkflowClient
# Create the LightlyOne client to connect to the API.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Let's fetch the dataset we created above.
client.set_dataset_id_by_name(dataset_name="videos-datapool")
# Schedule the run.
client.schedule_compute_worker_run(
worker_config={
"use_datapool": True,
"enable_training": False,
},
selection_config={
"n_samples": 50,
"strategies": [
{
"input": {
"type": "EMBEDDINGS",
},
"strategy": {
"type": "DIVERSITY",
},
}
],
},
)The samples selected in the second run will be uploaded to the dataset under a new tag in the LightlyOne Platform. The selected samples from all runs will be available under the initial-tag of the dataset.
What Happens During a Crash When Working with a Datapool?
At the end of a run, the following steps happen:
- The selected samples will be uploaded
- After uploading, a new tag is created with a timestamp and the
initial-tagis updated to contain all images (previously selected as well as newly added images) - The dataset is fully updated
There are two common scenarios to consider:
If the worker crashes before step 1 (samples are being uploaded), you can assume that the run had no impact at all on the dataset in the LightlyOne Platform. You can just create a new run with the same config.
If the worker crashes during step 1, the samples have been uploaded, but the dataset has not been updated with a new tag. On the LightlyOne Platform, it might appear as if the dataset is not completed. In order to resolve that issue you can create a new run. When the new run finishes uploading the samples it will create a tag with all the newly added images (including the partially uploaded samples from the crashed run).
As you see, creating a new run is the recommended way to resolve an issue after a crash when working with a dataset that uses the datapool feature.
Process All Data
If you want to search all data in your bucket for new samples instead of only newly added data, then set process_all to True in the worker_config. This is useful if you want to increase the dataset size but do not yet have any new data in your bucket or if your selection requirements have changed and you updated your selection configuration.
The process_all flag can be set as follows:
from lightly.api import ApiWorkflowClient
# Create the LightlyOne client to connect to the API.
client = ApiWorkflowClient(token="MY_LIGHTLY_TOKEN")
# Let's fetch the dataset we created above.
client.set_dataset_id_by_name(dataset_name="videos-datapool")
# Schedule the run.
client.schedule_compute_worker_run(
worker_config={
"use_datapool": True,
"datasource": {
"process_all": True,
},
"enable_training": False,
},
selection_config={
"n_samples": 50,
"strategies": [
{
"input": {
"type": "EMBEDDINGS",
},
"strategy": {
"type": "DIVERSITY",
},
}
],
},
)Common Cases Where the LightlyOne Worker Run is Aborted
There are certain cases where the LightlyOne Worker is aborted when the datapool feature is used. You can find more information in Common Errors that Abort the LightlyOne Worker.
Updated 8 months ago