
Selection Strategy Combination
Selection Algorithm
The Lightly selection algorithm selects the samples greedily, i.e. one sample after the other. This is the only algorithm that can scale to millions of samples.
In each step, it selects the samples that lead to the highest fulfillment of the overall selection objective. The overall objective is the product of the objectives of each strategy. Taking the product has the advantage that the scale of each strategy objective is irrelevant, as multiplying all scores of one strategy by a constant has the same effect as multiplying the overall scores by a constant: It does not change the order of the overall scores.
This is shown in the example below with a Visual Diversity and Active Learning strategy. The visual diversity strategy computes how well each sample fulfills the visual diversity objective. At the same time, the active learning strategy computes how well the active learning score objective is fulfilled. Consider a case with 3 samples:
| Visual Diversity Objective | Active Learning Score Objective | Overall Score | |
|---|---|---|---|
| sample 1 | 21.0 | 10.3 | 216.30 |
| sample 2 | 20.8 | 10.8 | 224.64 |
| sample 3 | 20.5 | 10.9 | 223.45 |
The sample selected by the Lightly selection algorithm is sample 2 in this case, as it has the highest overall score.
The strategy strength of each strategy is applied as the exponent of the strategy objective: overall_score = product(strategy.objective ^ strategy.strength for strategy in strategies).
Thresholding is done before the combination selection process, thus it is excluded in the combination selection of the other strategies.
Strategy Objectives
In every step of the selection process, each strategy calculates for each unselected sample, which objective value it would cause if it was selected. The definition of the objective depends on the type of strategy.
Diversity
The Diversity strategy has the objective of maximizing the sum of diversities between samples. The diversity of a sample is the distance from it to its closest neighbor in the embedding space. The following plot visualizes the objective as the sum of the lengths of the green lines.
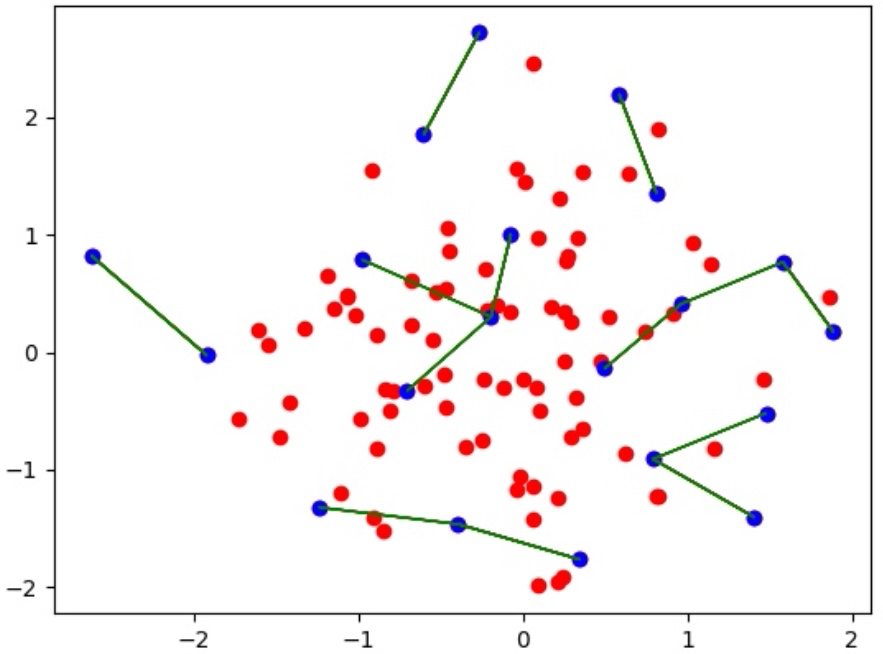
Distance between selected samples (blue) is depicted as green lines. Red samples are unselected samples.
Weights
Weighting has the objective of maximizing the sum of input values of the selected samples. E.g. if the selected samples have inputs values of 1, 2, and 0.5 respectively, then the objective value is 1+2+0.5=3.5.
Balance
The Balance strategy aims to maximize the similarity between the distribution of the selected samples and the target distribution.
We calculate the objective as 1 / CrossEntropy(distribution_selected_samples, target_distribution).
In each selection step, it is calculated for each new sample, which new distribution among selected samples it would cause if it was selected, and which new objective value this would cause. As new samples might worsen the distribution, the objective value can decrease.
Similarity
The Similarity strategy first calculates the maximum cosine similarity from each sample to the key samples. Then it treats this similarity similar to the Weights strategy and has the objective of maximizing the sum of similarities.
Updated 7 months ago